10 Tablas de frecuencia
Las tablas de frecuencia son muy utilizadas en estadística y R permite crear tablas de una forma sencilla. En este capítulo se explican las principales funciones para la elaboración de tablas.
10.1 Tabla de contingencia con table
La función table sirve para construir tablas de frecuencia de una vía, a continuación la estrctura de la función.
Los parámetros de la función son:
...espacio para ubicar los nombres de los objetos (variables o vectores) para los cuales se quiere construir la tabla.exclude: vector con los niveles a remover de la tabla. Siexclude=NULLimplica que se desean ver losNA, lo que equivale auseNA = 'always'.useNA: instrucción de lo que se desea con losNA. Hay tres posibles valores para este parámetro:'no'si no se desean usar,'ifany'y'always'si se desean incluir.
Ejemplo: tabla de frecuencia de una vía
Considere el vector fuma mostrado a continuación y construya una tabla de frecuencias absolutas para los niveles de la variable frecuencia de fumar.
fuma <- c('Frecuente', 'Nunca', 'A veces', 'A veces', 'A veces',
'Nunca', 'Frecuente', NA, 'Frecuente', NA, 'hola',
'Nunca', 'Hola', 'Frecuente', 'Nunca')A continuación se muestra el código para crear la tabla de frecuencias para la variable fuma.
## fuma
## A veces Frecuente hola Hola Nunca
## 3 4 1 1 4De la tabla anterior vemos que NO aparece el conteo de los NA, para obtenerlo usamos lo siguiente.
## fuma
## A veces Frecuente hola Hola Nunca <NA>
## 3 4 1 1 4 2Vemos que hay dos niveles errados en la tabla anterior, Hola y hola. Para construir la tabla sin esos niveles errados usamos lo siguiente.
## fuma
## A veces Frecuente Nunca <NA>
## 3 4 4 2Por último construyamos la tabla sin los niveles errados y los NA, a esta última tabla la llamaremos tabla1 para luego poder usarla. Las instrucciones para hacer esto son las siguientes.
## fuma
## A veces Frecuente Nunca
## 3 4 4table(var1, var2), la variable 1 quedará por filas mientras que la variable 2 estará en las columnas.
Ejemplo: tabla de frecuencia de dos vías
Considere otro vector sexo mostrado a continuación y construya una tabla de frecuencias absolutas para ver cómo se relaciona el sexo con fumar del ejemplo anterior.
sexo <- c('Hombre', 'Hombre', 'Hombre', NA, 'Mujer',
'Casa', 'Mujer', 'Mujer', 'Mujer', 'Hombre', 'Mujer',
'Hombre', NA, 'Mujer', 'Mujer')Para construir la tabla solicitada usamos el siguiente código.
## fuma
## sexo A veces Frecuente hola Hola Nunca
## Casa 0 0 0 0 1
## Hombre 1 1 0 0 2
## Mujer 1 3 1 0 1De la tabla anterior vemos que aparecen niveles errados en fuma y en sexo, para retirarlos usamos el siguiente código incluyendo en el parámetro exclude un vector con los niveles que NO deseamos en la tabla.
## fuma
## sexo A veces Frecuente Nunca
## Hombre 1 1 2
## Mujer 1 3 110.2 Función prop.table
La función prop.table se utiliza para crear tablas de frecuencia relativa a partir de tablas de frecuencia absoluta, la estructura de la función se muestra a continuación.
x: tabla de frecuencia.margin: valor de 1 si se desean proporciones por filas, 2 si se desean por columnas,NULLsi se desean frecuencias globales.
Ejemplo: tabla de frecuencia relativa de una vía
Obtener la tabla de frencuencia relativa para la tabla1.
Para obtener la tabla solicitada se usa el siguiente código.
## fuma
## A veces Frecuente Nunca
## 0.2727273 0.3636364 0.3636364Ejemplo: tabla de frecuencia relativa de dos vías
Obtener la tabla de frencuencia relativa para la tabla2.
Si se desea la tabla de frecuencias relativas global se usa el siguiente código. El resultado se almacena en el objeto tabla3 para ser usado luego.
## fuma
## sexo A veces Frecuente Nunca
## Hombre 0.1111111 0.1111111 0.2222222
## Mujer 0.1111111 0.3333333 0.1111111Si se desea la tabla de frecuencias relativas marginal por columnas se usa el siguiente código.
## fuma
## sexo A veces Frecuente Nunca
## Hombre 0.5000000 0.2500000 0.6666667
## Mujer 0.5000000 0.7500000 0.333333310.3 Función addmargins
Esta función se puede utilizar para agregar los totales por filas o por columnas a una tabla de frecuencia absoluta o relativa. La estructura de la función es la siguiente.
A: tabla de frecuencia.margin: valor de 1 si se desean proporciones por columnas, 2 si se desean por filas,NULLsi se desean frecuencias globales.
Ejemplo
Obtener las tablas tabla3 y tabla4 con los totales margines global y por columnas respectivamente.
Para hacer lo solicitado usamos las siguientes instrucciones.
## fuma
## sexo A veces Frecuente Nunca Sum
## Hombre 0.1111111 0.1111111 0.2222222 0.4444444
## Mujer 0.1111111 0.3333333 0.1111111 0.5555556
## Sum 0.2222222 0.4444444 0.3333333 1.0000000## fuma
## sexo A veces Frecuente Nunca
## Hombre 0.5000000 0.2500000 0.6666667
## Mujer 0.5000000 0.7500000 0.3333333
## Sum 1.0000000 1.0000000 1.0000000margin de las funciones prop.table y addmargins significan lo contrario.
10.4 Función hist
Construir tablas de frecuencias para variables cuantitativas es necesario en muchos procedimientos estadísticos, la función hist sirve para obtener este tipo de tablas. La estructura de la función es la siguiente.
Los parámetros de la función son:
x: vector numérico.breaks: vector con los límites de los intervalos. Si no se especifica se usar la regla de Sturges para definir el número de intervalos y el ancho.include.lowest: valor lógico, siTRUEuna observación \(x_i\) que coincida con un límite de intervalo será ubicada en el intervalo izquierdo, siFALSEserá incluída en el intervalo a la derecha.right: valor lógico, siTRUElos intervalos serán cerrados a derecha de la forma \((lim_{inf}, lim_{sup}]\), si esFALSEserán abiertos a derecha.plot: valor lógico, siFALSEsólo se obtiene la tabla de frecuencias mientras que conTRUEse obtiene la representación gráfica llamada histograma.
Ejemplo
Genere 200 observaciones aleatorias de una distribución normal con media \(\mu=170\) y desviación \(\sigma=5\), luego construya una tabla de frecuencias para la muestra obtenida usando (a) la regla de Sturges y (b) tres intervalos con límites 150, 170, 180 y 190.
Primero se construye el vector x con las observaciones de la distribución normal por medio de la función rnorm y se especifica la media y desviación solicitada. Luego se aplica la función hist con el parámetro breaks='Sturges', a continuación el código utilizado.
## $breaks
## [1] 155 160 165 170 175 180 185 190
##
## $counts
## [1] 4 29 67 67 26 6 1
##
## $density
## [1] 0.004 0.029 0.067 0.067 0.026 0.006 0.001
##
## $mids
## [1] 157.5 162.5 167.5 172.5 177.5 182.5 187.5
##
## $xname
## [1] "x"
##
## $equidist
## [1] TRUE
##
## attr(,"class")
## [1] "histogram"El objeto res1 es una lista donde se encuentra la información de la tabla de frecuencias para x. Esa lista tiene en el elemento breaks los límites inferior y superior de los intervalos y en el elemento counts están las frecuencias de cada uno de los intervalos.
Para obtener las frecuencias de tres intervalos con límites 150, 170, 180 y 190 se especifica en el parámetros breaks los límites. El código para obtener la segunda tabla de frecuencias se muestra a continuación.
## $breaks
## [1] 150 170 180 190
##
## $counts
## [1] 100 93 7
##
## $density
## [1] 0.0250 0.0465 0.0035
##
## $mids
## [1] 160 175 185
##
## $xname
## [1] "x"
##
## $equidist
## [1] FALSE
##
## attr(,"class")
## [1] "histogram"Ejemplo
Construya el vector x con los siguientes elementos: 1.0, 1.2, 1.3, 2.0, 2.5, 2.7, 3.0 y 3.4. Obtenga varias tablas de frecuencia con la función hist variando los parámetros include.lowest y right. Use como límite de los intervalos los valores 1, 2, 3 y 4.
Lo primero que debemos hacer es crear el vector x solicitado así:
En la Figura 10.1 se muestran los 9 puntos y con color azul se representan los límites de los intervalos.
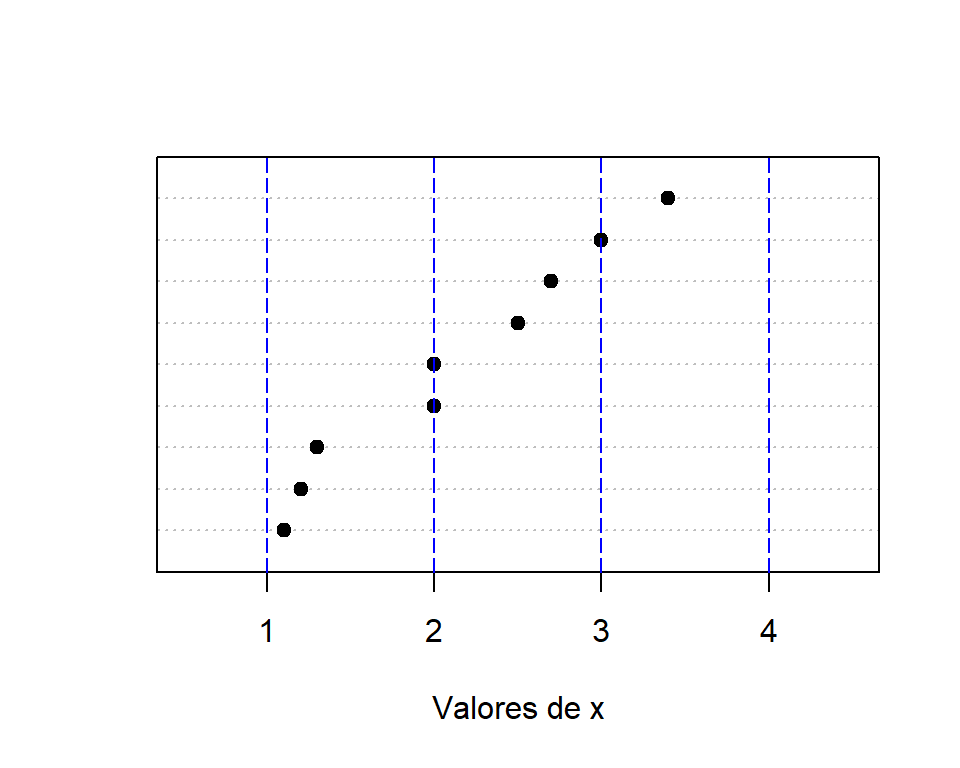
Figure 10.1: Ubicación de los puntos del ejemplo con límites en color azul.
A continuación se presenta el código para obtener la tabla de frecuencia usando rigth=TRUE, los resultados se almacenan en el objeto res3 y se solicitan sólo los dos primeros elementos que corresponden a los límites y frecuencias.
## $breaks
## [1] 1 2 3 4
##
## $counts
## [1] 5 3 1Ahora vamos a repetir la tabla pero usando rigth=FALSE para ver la diferencia, en res4 están los resultados.
## $breaks
## [1] 1 2 3 4
##
## $counts
## [1] 3 4 2Al comparar los últimos dos resultados vemos que la primera frecuencia es 5 cuando right=TRUE porque los intervalos se consideran cerrados a la derecha.
Ahora vamos a construir una tabla de frecuencia usando FALSE para los parámetros include.lowest y right.
## $breaks
## [1] 1 2 3 4
##
## $counts
## [1] 3 4 2De este último resultado se ve claramente el efecto de los parámetros include.lowest y right en la construcción de tablas de frecuencia.
EJERCICIOS
Use funciones o procedimientos (varias líneas) de R para responder cada una de las siguientes preguntas.
En el Cuadro 9.2 se presenta una base de datos sencilla. Lea la base de datos usando la funcion read.table y construya lo que se solicita a continuación.
- Construya una tabla de frecuencia absoluta para la variable pasatiempo.
- Construya una tabla de frecuencia relativa para la variable fuma.
- Construya una tabla de frecuencia relativa para las variables pasatiempo y fuma.
- ¿Qué porcentaje de de los que no fuman tienen como pasatiempo la lectura.
- ¿Qué porcentaje de los que corren no fuman?