17 Selección de la distribución
En este capítulo se mostrará cómo usar R para obtener obtener el listado de las distribuciones que mejor se ajustan a una variable.
17.1 Función fitDists
La función fitDist del paquete gamlss permite explorar las distribuciones que mejor explican un conjunto de datos.
La función fitDist tiene la siguiente estructura:
fitDist(y, k = 2,
type = c("realAll", "realline", "realplus",
"real0to1", "counts", "binom"))El parámetro y sirve para ingresar el vector con la información; k=2 es la penalización por cada parámetro estimado para calcular el \(GAIC\), por defecto es 2; y el parámetro type sirve para indicar el tipo de distribución, los posibles valores son:
realAll: para hacer la búsqueda en todas las distribuciones disponibles en gamlss.realline: para variables en \(\Re\).realplus: para variables en \(\Re^+\).real0to1: para variables en el intervalo \((0, 1)\).counts: para variables de conteo.binom: para variables de tipo binomial.
Ejemplo
Generar \(n=100\) observaciones de una gamma con parámetro \(\mu=2\) y parámetro \(\sigma=0.5\) y verificar si la función fitDist logra identificar que los datos fueron generados de una distribución gamma. Use \(k=2\) para calcular el \(AIC\).
Solución
Para generar la muestra aleatoria solicitada se fijó la semilla con el objetivo de que el lector pueda obtener los mismos resultados de este ejemplo. En este ejemplo vamos a usar la función rGA del paquete gamlss para simular la muestra aleatoria ma.
library(gamlss)
n <- 500
set.seed(12345)
ma <- rGA(n=n, mu=2, sigma=0.5)Para ver los datos simulados vamos a construir un histograma sencillo y en el eje horizontal se van a destacar los datos usando una especie de “tapete” con la función rug.
hist(x=ma, freq=FALSE, main="")
rug(x=ma, col="deepskyblue3")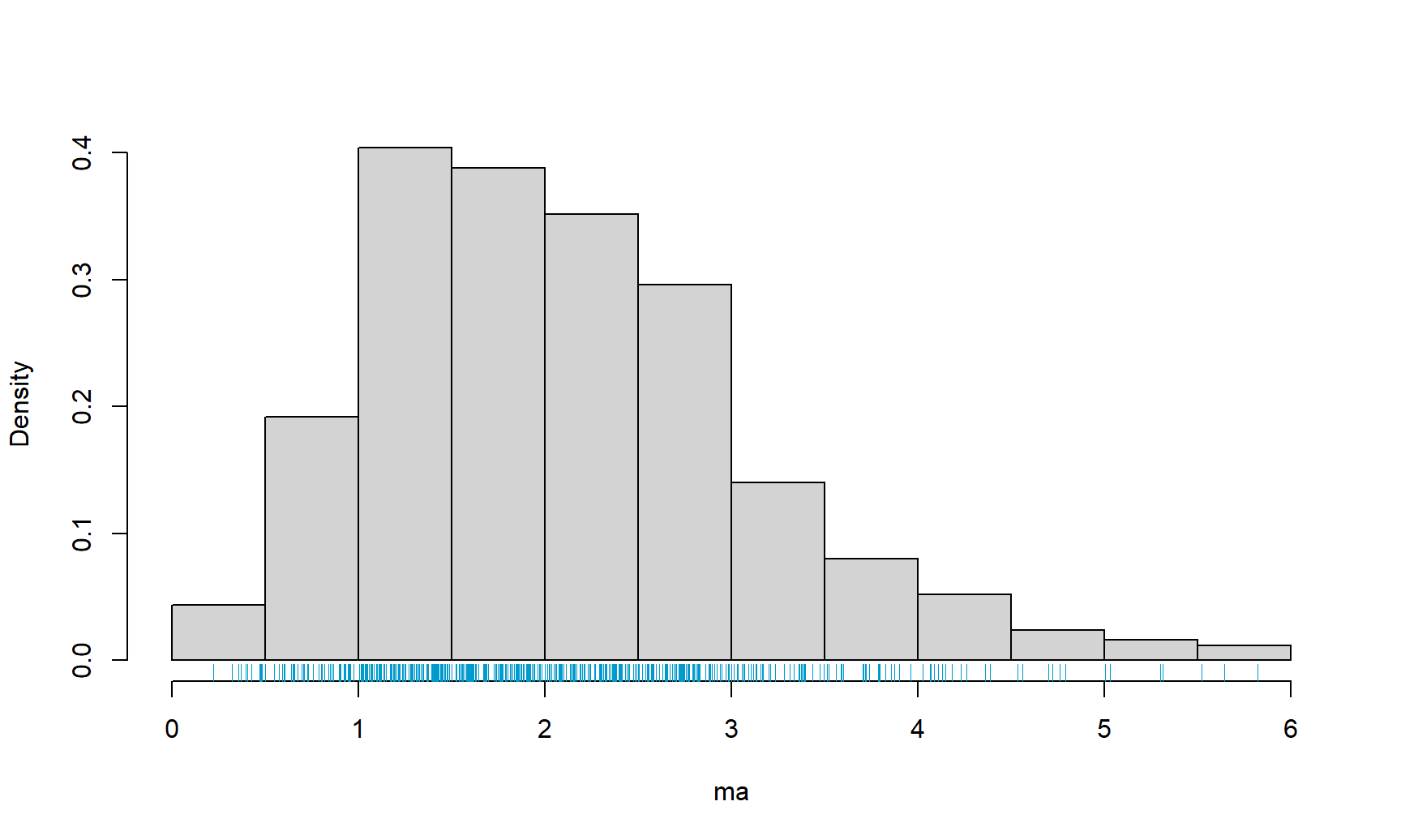
Figure 17.1: Histograma para la muestra simulada con la densidad de una Gamma(mu=4.308, sigma=0.6682).
Se va a usar la función fitDist con type='realplus' porque se sabemos que la muestra aleatoria tiene valores en \(\Re^+\). Los resultados de almacenan en el objeto modelos y para obtener la lista de los mejores modelos con su respectivo \(AIC\) se escribe en la consola modelos$fits. Abajo el código usado.
modelos <- fitDist(y=ma, type='realplus', k=2)##
|
| | 0%
|
|=== | 4%
|
|====== | 9%
|
|========= | 13%
|
|============ | 17%
|
|=============== | 22%
|
|================== | 26%
|
|===================== | 30%
|
|======================== | 35%
|
|=========================== | 39%
|
|============================== | 43%
|
|================================= | 48%
|
|===================================== | 52%
|
|======================================== | 57%
|
|=========================================== | 61%
|
|============================================== | 65%
|
|================================================= | 70%
|
|==================================================== | 74%
|
|======================================================= | 78%
|
|========================================================== | 83%Error in solve.default(oout$hessian) :
## Lapack routine dgesv: system is exactly singular: U[4,4] = 0
##
|
|============================================================= | 87%Error in solve.default(oout$hessian) :
## Lapack routine dgesv: system is exactly singular: U[4,4] = 0
##
|
|================================================================ | 91%
|
|=================================================================== | 96%
|
|======================================================================| 100%modelos$fits## GA GG BCCGo BCCG GIG GB2 BCPEo BCPE
## 1368.503 1368.561 1369.284 1369.284 1370.503 1370.562 1370.967 1370.967
## BCT BCTo WEI WEI2 WEI3 exGAUS LOGNO LOGNO2
## 1371.284 1371.284 1376.365 1376.365 1376.365 1383.357 1401.925 1401.925
## IG IGAMMA EXP PARETO2 GP PARETO2o
## 1418.277 1488.333 1738.337 1740.337 1740.338 1740.339De la lista anterior se observa que la función gamma está en el primer lugar con un \(AIC=1368.5027744\) con el menor \(AIC\). Esto significa que la distribución gamma explica mejor los datos de la muestra, y esto coincide con la realidad, ya que la muestra fue generada de una distribución gamma.
Para obtener los valores estimados de \(\mu\) y \(\sigma\) se usa el siguiente código.
modelos$mu## [1] 2.088272modelos$sigma## [1] 0.4945352Por último vamos a dibujar el histograma para la muestra aleatoria y vamos a agregar la densidad de la distribución gamma identificada como la distribución que mejor explica el comportamiento de la variable. Para hacer lo deseado se usa la función histDist del paquete gamlss, sólo es necesario ingresar los datos y el nombre de la distribución. Abajo el código usado.
h <- histDist(y=ma, family=GA, main='', xlab='x', ylab='Densidad',
line.col='deepskyblue3', line.wd=4, ylim=c(0, 0.45))
rug(x=ma, col="deepskyblue3")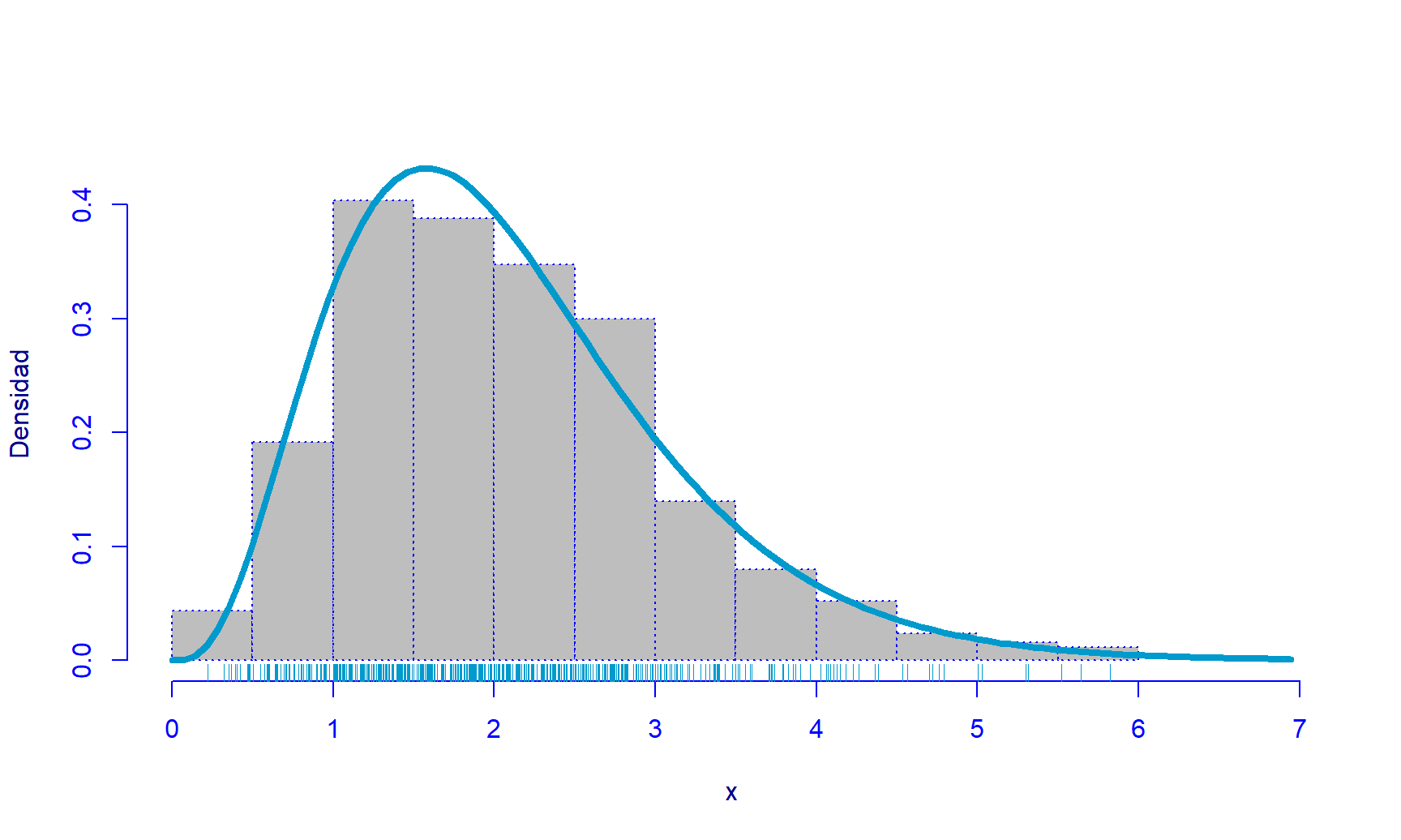
Figure 17.2: Histograma para la muestra simulada con la densidad de una Gamma(mu=2.088, sigma=0.495).
En la Figura 17.2 se presenta el histograma para muestra aleatoria y la densidad de la gamma que mejor explica estos datos. Se observa claramente que la curva de densidad azul acompaña la forma del histograma.