2 Transformaciones
En este capítulo se muestra cómo una transformación de la variable respuesta o de las covariables puede mejorar el modelo.
Transformaciones para linealizar el modelo
En algunas ocasiones el modelo teórico de los datos tiene una estructura matemática que puede ser linealizable al transformar \(Y\) y/o \(X\). En la siguiente tabla se muestran algunos de los casos en los cuales se puede linealizar el modelo.
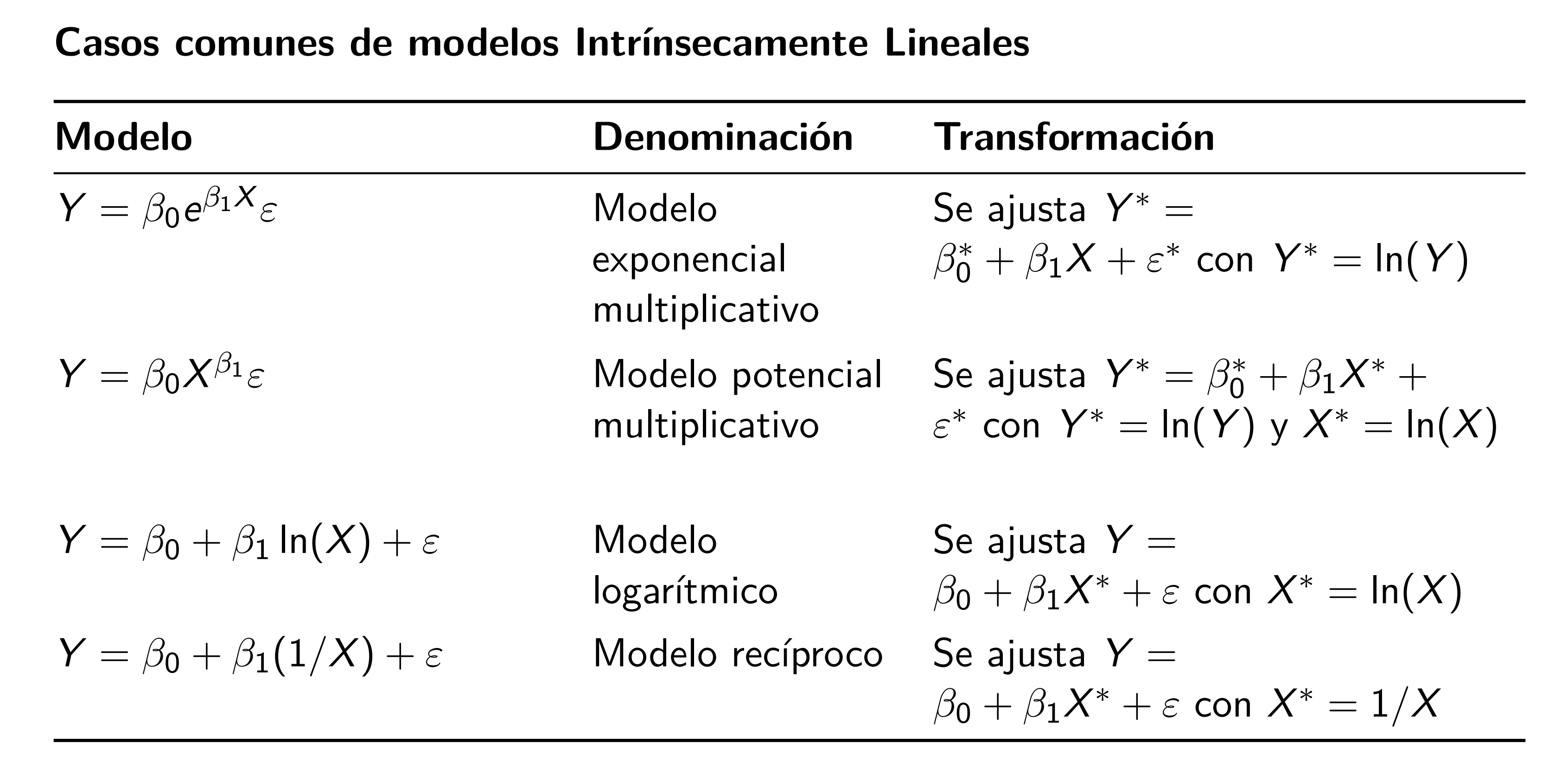
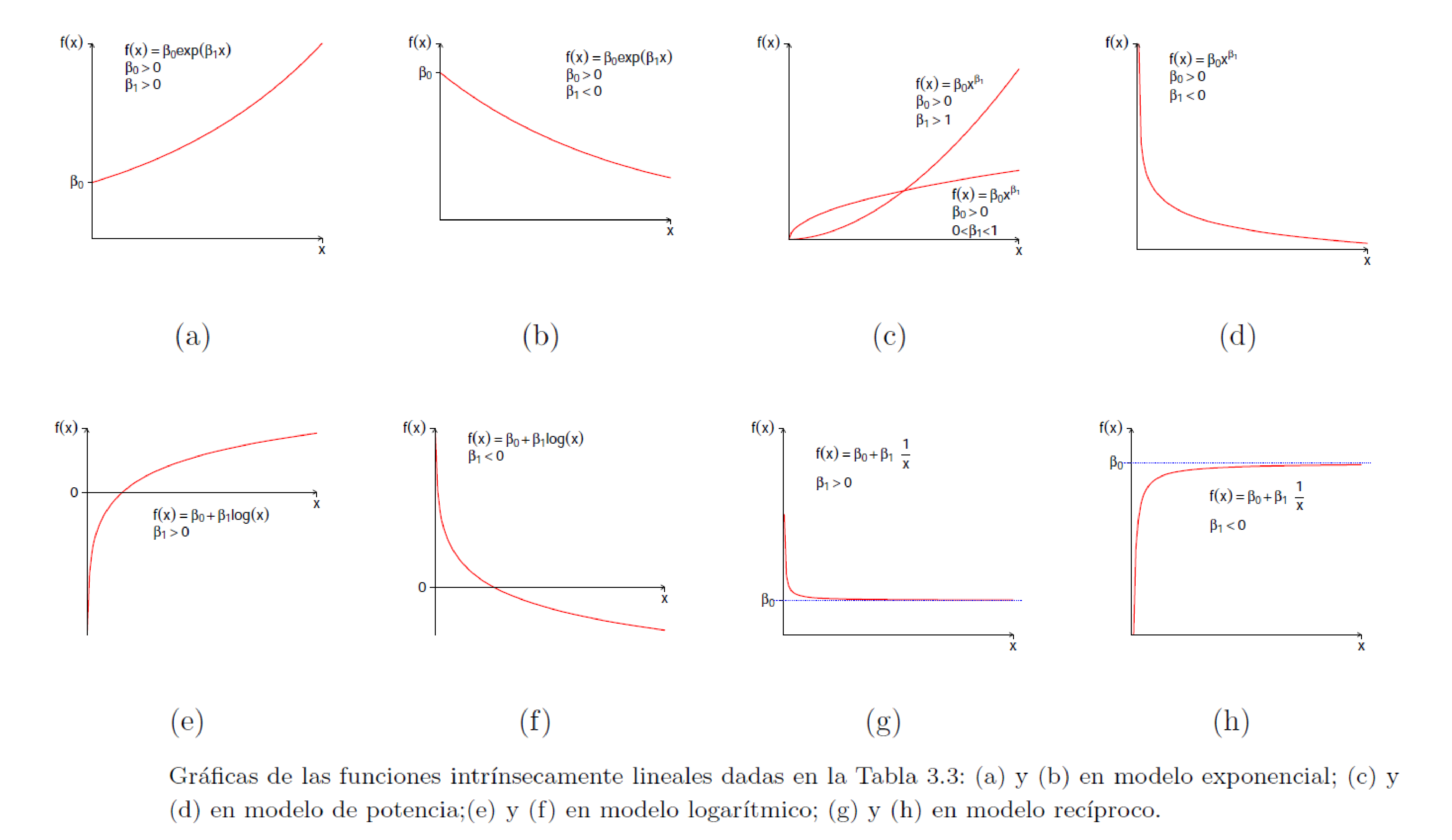
En la siguiente figura se muestran los patrones de los modelos que se pueden linealizar.
Ejemplo
Este ejemplo está basado en el ejericio 5.1 propuesto en el libro E. &. V. Montgomery D. & Peck (2006) se presenta una base de datos de un estudio de cómo influye la temperatura (°C) sobre la viscosidad (mPa s) de las mezclas de tolueno y tetralina. La base de datos cuenta con un total de 50 observaciones, a continuación se muestran las primeras seis observaciones de la base.
## temp visc
## 1 85.63 0.27
## 2 64.48 0.40
## 3 42.12 0.62
## 4 76.73 0.31
## 5 58.18 0.46
## 6 42.35 0.60- Crear un diagrama de dispersión. ¿Parece apropiado usar una línea recta para modelar los datos?
- Ajuste el modelo de línea recta. Calcule las estadísticas resumidas y las gráficas residuales. ¿Cuáles son sus conclusiones sobre la adecuación del modelo?
- Los principios básicos de la química física sugieren que la viscosidad es una función exponencial de la temperatura. Repita la parte b usando la transformación adecuada según esta información.
- ¿Cuál modelo se debería usar? Escriba la ecuación del modelo.
- Con el modelo elegido, calcule \(\widehat{Visco}\) para \(Temp=0\) y para \(Temp=50\).
Solución
- Diagrama de dispersión
library(ggplot2)
ggplot(datos, aes(x=temp, y=visc)) +
geom_point() + theme_light() +
xlim(0, 120) +
labs(y="Viscocidad (mPa s)", x="Temperatura (°C)")![]()
- Ajustando el modelo de línea recta.
Los estadísticos de resumen se obtiene así:
##
## Call:
## lm(formula = visc ~ temp, data = datos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.048849 -0.026135 -0.006075 0.027772 0.079221
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.0295982 0.0101903 101.04 <2e-16 ***
## temp -0.0092809 0.0001646 -56.38 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03356 on 98 degrees of freedom
## Multiple R-squared: 0.9701, Adjusted R-squared: 0.9698
## F-statistic: 3179 on 1 and 98 DF, p-value: < 2.2e-16De la tabla anterior se observa que:
- La temperatura es significativa porque valor-p es < 2e-16.
- Por cada grado °C en que aumente la temperatura, la viscocidad disminuye en 0.00928098 unidades.
- El \(R^2\) es alto, presenta un valor de 0.9701.
- El modelo m1 es significativo porque valor-p es < 2.2e-16.
Para ver los residuales del modelo se hace lo siguiente:
![]()
Claramente los residuales muestran un patrón de u, eso indica que hay algo errado con el modelo m1.
##
## Shapiro-Wilk normality test
##
## data: res_m1
## W = 0.93894, p-value = 0.0001661- Vamos a entrenar un modelo asumiendo un patrón exponencial multiplicativo \(Y = \beta_0 e^{\beta_1X}\varepsilon\).
Para poder ajustar este modelo en R, es necesario transformar la variable respuesta, es decir, vamos a entrenar con \(Y^*=\log(Y)\). En otras palabras, vamos a aplicar \(\log()\) a ambos lados del modelo exponencial multiplicativo \(Y = \beta_0 e^{\beta_1X}\varepsilon\) y lo que obtiene es:
\[ Y^* = \beta_0^* + \beta_1 X + \varepsilon^*, \]
donde el nuevo intercepto es \(\beta_0^*=\log(\beta_0)\) y el nuevo error es \(\varepsilon^*=\log(\varepsilon)\). El valor de \(\beta_1\) es el mismo en el modelo original y en el modelo transformado.
Al ajustar el modelo transformado vamos a obtener un intercepto estimado \(\hat{\beta}_0^*\) y una pendiente estimada \(\hat{\beta}_1\).
Si queremos obtener \(\hat{\beta}_0\), debemos despejar de la ecuación \(\beta_0^*=\log(\beta_0)\) el valor de \(\hat{\beta}_0\).Ajustemos el modelo m2.
Los estadísticos de resumen se obtiene así:
##
## Call:
## lm(formula = log(visc) ~ temp, data = datos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.093451 -0.017099 0.001985 0.017799 0.096605
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.3656552 0.0098882 36.98 <2e-16 ***
## temp -0.0199453 0.0001597 -124.87 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03257 on 98 degrees of freedom
## Multiple R-squared: 0.9938, Adjusted R-squared: 0.9937
## F-statistic: 1.559e+04 on 1 and 98 DF, p-value: < 2.2e-16De la tabla anterior se observa que:
- La temperatura es significativa porque valor-p es < 2e-16.
- Por cada grado °C en que aumente la temperatura, la log(viscocidad) disminuye en 0.0199453 unidades.
- El \(R^2\) es alto, presenta un valor de 0.9938.
- El modelo m2 es significativo porque valor-p es < 2.2e-16.
Para ver los residuales del modelo se hace lo siguiente:
![]()
##
## Shapiro-Wilk normality test
##
## data: res_m2
## W = 0.99063, p-value = 0.7151Comparemos las líneas o modejos ajustados m1 y m2 con un diagrama de dispersión.
par(mfrow=c(1, 2))
plot(x=datos$temp, y=datos$visc, pch=20, cex=0.8,
xlab="Temperatura (°C)", ylab="Viscocidad", main="M1")
abline(m1, col="purple", lwd=2)
plot(x=datos$temp, y=log(datos$visc), pch=20, cex=0.8,
xlab="Temperatura (°C)", ylab="log(Viscocidad)", main="M2")
abline(m2, col="palegreen3", lwd=2)![]()
- ¿Cuál modelo se debería usar? Escriba la ecuación del modelo.
Usando los resultados de summary de m2 es posible escribir la ecuación ajustada para el modelo modelo transformado y para el modelo exponencial multiplicativo.
Modelo transformado:
\[ \widehat{Visco^*} = \widehat{\log(Visco)} = 0.3657 - 0.0199 \, Temp, \]
Modelo exponencial multiplicativo:
\[ \widehat{Visco} = 1.4415 \, e^{- 0.0199 \, Temp}, \]
donde \(1.4415=\exp(0.3657)\).
- Con el modelo elegido, calcule \(\widehat{Visco}\) para \(Temp=0\) y para \(Temp=50\).
- La cantidad \(\widehat{Visco} \vert Temp=0\) no se debe calcular.
- La cantidad \(\widehat{Visco} \vert Temp=50\) es \(1.4415 \, e^{- 0.0199 \times 50} = 0.5330\).
visco_hat <- function(x) 1.4415 * exp(-0.0199*x)
plot(x=datos$temp, y=datos$visc, pch=20, cex=0.8,
xlab="Temperatura (°C)", ylab="Viscocidad",
main="Modelo final")
curve(expr=visco_hat(x), add=TRUE, col="tomato")![]()