3 Regresión lineal múltiple
En este capítulo se presenta una descripción breve del modelo de regresión lineal múltiple y la forma de estimar los parámetros del modelo con R.
Modelo estadístico
El modelo estadístico en regresión lineal múltiple es una generalización del regresión lineal simple para \(k\) covariables. El modelo en este caso se puede escribir de dos formas como se muestra a continuación.
- En esta forma la variable respuesta \(Y\) se expresa como una suma de \(\beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \cdots + \beta_k X_{ki}\) y un error aleatorio \(e_i\) el cual tiene distribución \(N(0, \sigma^2)\). El modelo en esta forma se puede expresar como sigue.
\[\begin{align} \label{mod1} Y_i &= \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \cdots + \beta_k X_{ki} + \epsilon_i, \\ \epsilon_i &\sim N(0, \sigma^2) \end{align}\]
- En esta forma la variable respuesta \(y\) tiene distribución normal con media que cambia en función de las variables \(x_k\) pero con varianza constante. El modelo en esta forma se puede expresar como sigue.
\[\begin{align} \label{mod2} Y_i &\sim N(\mu_i, \sigma^2), \\ \mu_i &= \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \cdots + \beta_k X_{ki}, \\ \sigma^2 &= \text{constante} \end{align}\]
En cualquiera de las dos formas el vector de parámetros del modelo es \(\boldsymbol{\theta}=(\beta_0, \beta_1, \cdots, \beta_k, \sigma)^\top\).
Ejemplo
Como ilustración vamos a usar los datos del ejemplo 3.1 del libro de E. &. V. Montgomery D. & Peck (2006). En el ejemplo 3.1 los autores ajustaron un modelo de regresión lineal múltiple para explicar el Tiempo necesario para que un trabajador haga el mantenimiento y surta una máquina dispensadora de refrescos en función de las variables Número de Cajas y Distancia.
Los datos del ejemplo están disponibles en el paquete MPV (por los apellidos de los autores). A continuación el código para cargar los datos y una muestra de las 6 primeras observaciones de la base de datos, en total se disponen de 20 observaciones.
## tiempo cantidad distancia
## 1 16.68 7 560
## 2 11.50 3 220
## 3 12.03 3 340
## 4 14.88 4 80
## 5 13.75 6 150
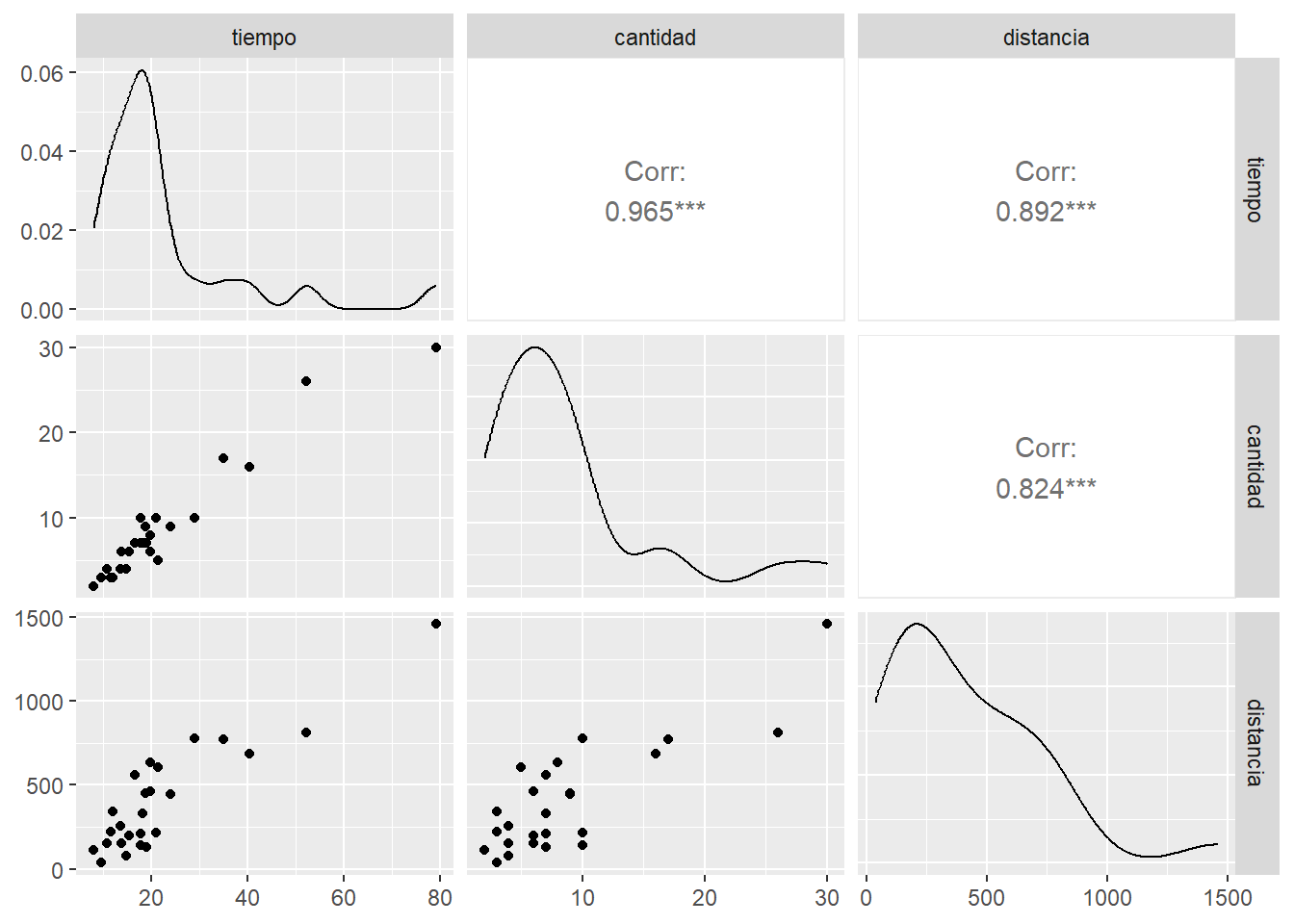
## 6 18.11 7 330Un gráfico esencial para explorar las relaciones entre las variables es el gráfico de dispersión por pares de variables.
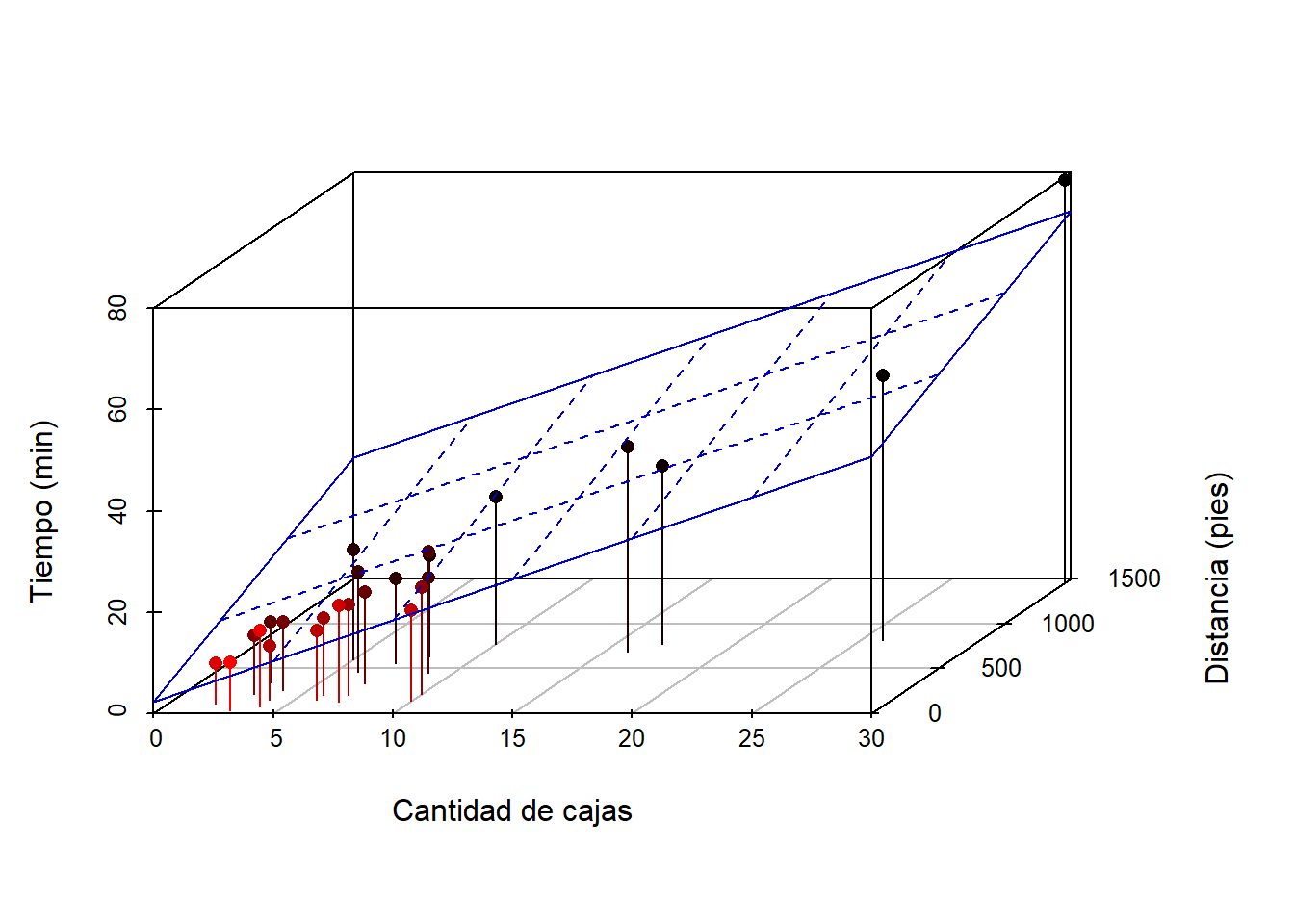
Un gráfico en 3d es obligratorio para explorar la relación entre las variables, este diagrama de puede obtener usando el paquete scatterplot3d. A continuación el código para construirlo.
library(scatterplot3d)
attach(softdrink)
scatterplot3d(x=cantidad, y=distancia, z=tiempo, pch=16, cex.lab=1,
highlight.3d=TRUE, type="h", xlab="Cantidad de cajas",
ylab="Distancia (pies)", zlab="Tiempo (min)")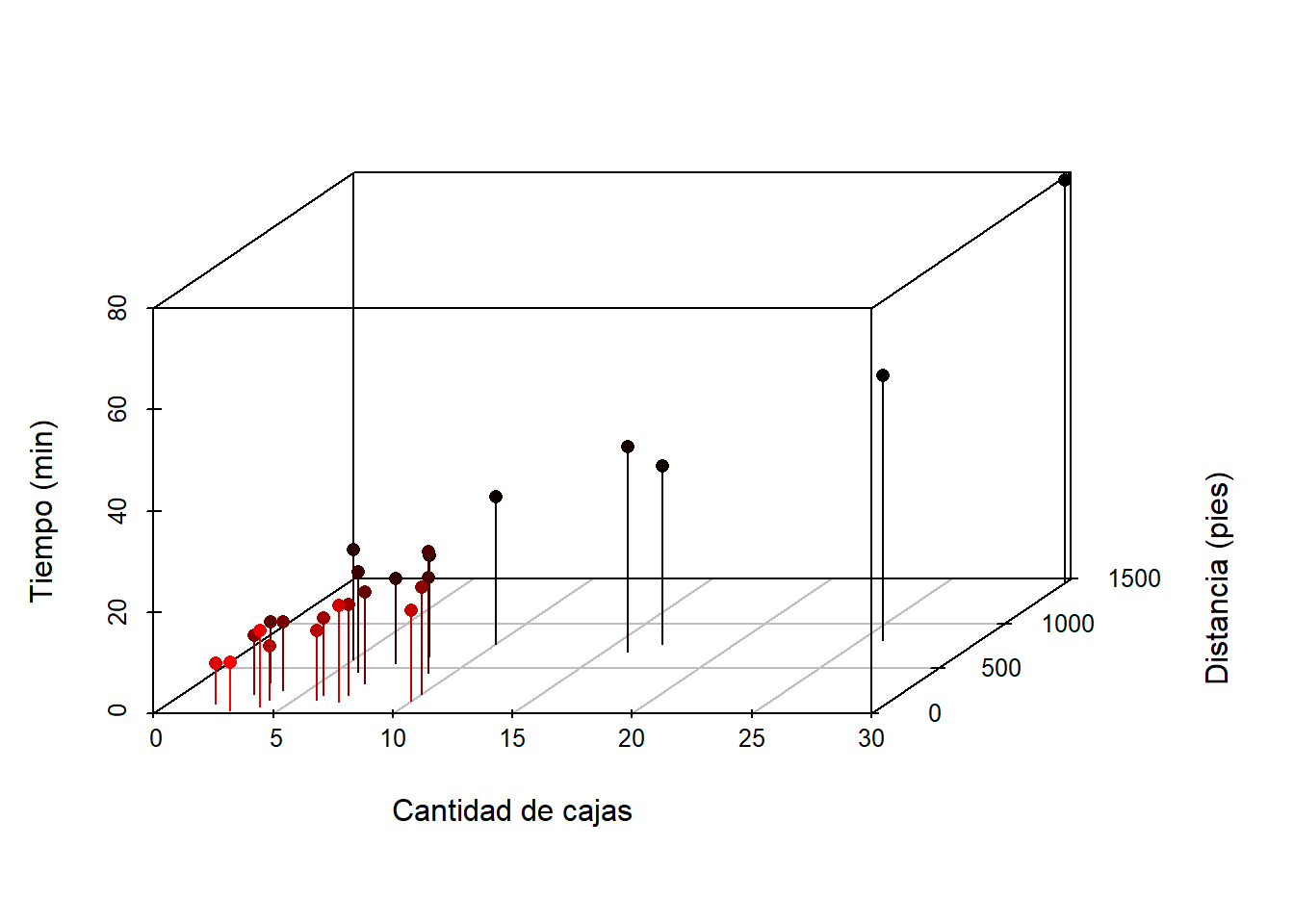
De la figura anterior se ve claramente que a medida que aumenta el número de cajas y la distancia los tiempos tienden a ser mayores.
El mismo diagrama de dispersión anterior se puede crear usando el paquete plotly. El lector puede jugar con el diagrama, puede moverlo, girarlo, acercarse y muchas cosas más, la curiosidad le mostrará las diferentes posibilidades.
library(plotly)
plot_ly(x=cantidad, y=distancia, z=tiempo, type="scatter3d", color=tiempo) %>%
layout(scene = list(xaxis = list(title = "Cantidad"),
yaxis = list(title = "Distancia (pies)"),
zaxis = list(title = "Tiempo (min)")))Otro gráfico de dispersión en 3d se puede construir usando el paquete rgl. A continuación está el código para obtener el diagrama de dispersión. De tarea se deja que el lector copie el código en la consola y reconstruya el gráfico.
library(rgl)
plot3d(x=cantidad, y=distancia, z=tiempo, type="s", col="pink",
xlab="Cantidad",
ylab="Distancia (pies)",
zlab="Tiempo (min)")Basándonos en el diagrama de dispersión 3d, el modelo que se va a ajustar se muestra a continuación.
\[\begin{align} Tiempo_i &\sim N(\mu_i, \sigma^2), \\ \mu_i &= \beta_0 + \beta_1 Cantidad_i + \beta_2 Distancia_i, \\ \sigma^2 &= \text{constante} \end{align}\]
Para ajustar (entrenar) el modelo anterior podemos usar la función lm como se muestra a continuación.
Luego de ajustar el modelo se debe solicitar la tabla de resumen del modelo y esto se puede hacer de la siguiente manera.
##
## Call:
## lm(formula = tiempo ~ cantidad + distancia, data = softdrink)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.7880 -0.6629 0.4364 1.1566 7.4197
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.341231 1.096730 2.135 0.044170 *
## cantidad 1.615907 0.170735 9.464 3.25e-09 ***
## distancia 0.014385 0.003613 3.981 0.000631 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.259 on 22 degrees of freedom
## Multiple R-squared: 0.9596, Adjusted R-squared: 0.9559
## F-statistic: 261.2 on 2 and 22 DF, p-value: 4.687e-16Con los resultados anteriores se puede expresar el modelo ajustado como se muestra a continuación.
\[\begin{align} \widehat{Tiempo}_i &\sim N(\hat{\mu}_i, \hat{\sigma}^2), \\ \hat{\mu}_i &= 2.341 + 1.616 \, Cantidad_i + 0.014 \, Distancia_i, \\ \hat{\sigma} &= 3.259 \end{align}\]
¿Cómo se pueden interpretar los efectos \(\hat{\beta}\)?
- Si el camión queda un pie más lejos (30.48 cm) de la máquina, se espera que el tiempo promedio de mantenimineto aumente en 0.014 minutos.
- Si el camión queda 100 pies más lejos (30.48 mt) de la máquina, se espera que el tiempo promedio de mantenimiento aumente en 1.4 minutos.
- Por cada caja adicional de refresco que se deba llevar, se espera que el tiempo promedio aumente en 1.616 minutos.
- Si el camión quedó a 0 pies de distancia y no hay que llevar cajas de refresco, se espera que el tiempo promedio de mantenimiento sea de 2.341 minutos.
Para incluir el plano de regresión que representa el modelo ajustado anterior se puede usar el siguiente código.
# Se crea el grafico 3d y se guarda en un objeto, por ejemplo mi_3d
mi_3d <- scatterplot3d(x=cantidad, y=distancia, z=tiempo, pch=16, cex.lab=1,
highlight.3d=TRUE, type="h", xlab="Cantidad de cajas",
ylab="Distancia (pies)", zlab="Tiempo (min)")
# Para agregar el plano usamos $plane3d( ) con argumento modelo ajustado
mi_3d$plane3d(mod, lty.box="solid", col="mediumblue")