11 Diagnóstico del modelo de regresión de efectos mixtos
El diagnóstico del modelo de regresión es uno de un conjunto de procedimientos disponibles para el análisis de regresión que buscan evaluar la validez de un modelo previamente ajustado. Esta evaluación puede ser una exploración de los supuestos estadísticos del modelo. El objetivo de este capitulo consiste en introducir al lector los distintos métodos de diagnostico del modelo de regresión.
11.1 Supuestos del modelo de regresión
Existen un conjunto de supuestos cuando se modela la relación entre una variable respuesta y un regresor. Estos supuestos son esencialmente condiciones que deben cumplirse. Cuando no es el caso, las estimaciones y predicciones pueden comportarse mal e incluso pueden tergiversar por completo los datos. El diagnóstico de regresión puede revelar el problema y, a menudo, señalar el camino hacia las soluciones.
Si un modelo de regresión ajustado representa adecuadamente los datos, sus residuos deberan:
- Tener varianza constante (homogeneidad de la varianza);
- Estar aproximadamente distribuidos de forma normal y;
- Ser independientes el uno del otro.
Por tanto los supuestos del modelo de regresión se examinan a partir de los residuos que resultan del ajuste previo.
11.2 Los residuos
Los residuos son la base de la mayoría de los métodos de diagnóstico. Estos pueden ser de distinto tipo. Los residuos más básicos son los denominados residuos ordinarios, ˆϵi, el cual se define como la diferencia entre el valor observado, yi, y su correspondiente valor estimado por el modelo, ˆμi, así:
ˆϵi=yi−ˆμi,i=1,2,...,n
donde ˆμi es igual a x′iˆβ. A continuación, se presenta una representación gráfica de ˆϵi:
Luego los residuos ordinarios se escalan con el fin de que su interpretación no dependa de las unidades de medida de la variable respuesta. El proceso de estandarización consiste en dividir el residuo ordinario, ˆϵi, por la expresión σ√(1−hi), donde σ corresponde a la desviación estandar verdadera y hi al leverage (en inglés). Los residuos obtenidos de esta manera se denominan como residuos estandarizados.
Sin embargo la verdadera desviación estándar rara vez se conoce. Por lo tanto, el escalado se puede realizar utilizando un estimador del mismo, es decir ˆσ. Los residuos obtenidos de esta manera se denominan como residuos estudentizados, los cuales a su vez se dividen en dos: los residuos internamente estudentizados y los residuos externamente estudentizados. La tabla a continuación, resume las formas básicas de los residuos escalados:
| Formula matemática | |
|---|---|
| Estandarizado | ˆϵiσ√(1−hi) |
| Internamente estudentizado | ˆϵiˆσ√(1−hi) |
| Externamente estudentizado | ˆϵiˆσ(−i)√(1−hi) |
| * En el residuo internamente estudentizado, ˆσ denota una estimación de σ basada en todas las observaciones; | |
| † En el residuo externamente estudentizado, ˆσ(−i) es una estimación obtenida luego de excluir la i-ésima observación de los cálculos. |
Se usara la base de datos hsb del paquete merTools para entender mejor de que tratan los residuos, así como también los métodos de diagnosticos que explicaremos más adelante en este capitulo. A continuación podra ver la base de datos a usar:
Se puede entender bien la lógica de los que son los residuos ajustando un modelo de regresión simple.
Suponga que se quiere poner en relación dos variables: la variable x1 que representa el nivel socio-económico de los estudiantes (ses), y la variable y, que es el rendimiento de los mismos estudiantes en una prueba de matemáticas (mathach). Para facilitar este análisis (y los posteriores) se asumira que x1 es una variable continua que toma valores entre -4 y +4, donde valores cercanos a 0 indican nivel socio-económico medio, cercanos a +4 indican nivel socio-económico alto y cercanos a -4 indican nivel socio-económico bajo.
El modelo de regresión simple aplicado a este ejemplo se puede representar así:
yi∼N(μi,σ2),μi=β0+β1x1i,σ2=constante
El codigó en R para ajustar el anterior modelo se presenta a continuación:
Modelo_simple <- lm(mathach ~ ses, data = hsb)
summary(Modelo_simple)##
## Call:
## lm(formula = mathach ~ ses, data = hsb)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.4382 -4.7580 0.2334 5.0649 15.9007
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 12.74740 0.07569 168.42 <2e-16 ***
## ses 3.18387 0.09712 32.78 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.416 on 7183 degrees of freedom
## Multiple R-squared: 0.1301, Adjusted R-squared: 0.13
## F-statistic: 1075 on 1 and 7183 DF, p-value: < 2.2e-16Luego, los residuos (en este caso los residuos ordinarios) se pueden obtener con las siguientes funciones genericas:
muestra_aleatoria$val_predicho <- predict(Modelo_simple)
muestra_aleatoria$res_ordinario <- residuals(Modelo_simple)La gráfica a continuación presenta los valores observados y estimados en el rendimiento de los estudiantes en una prueba de matemáticas según su nivel socio-económico, siendo la misma una representación gráfica similar a la presentada en la Figura 6.1:
## Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
## "none")` instead.
Figure 11.1: Valores obserados y estimados en el rendimiento en una prueba matemática según el nivel socio-económico del estudiante.
La gráfica anterior representa la relación existente entre el rendimiento académico y el nivel socio-económico del estudiante. Claramente se puede observar que a mayor nivel socio-económico, mejor es el rendimiento del estudiante. Una vez ajustado el modelo de regresión, y como se puede observar en la anterior gráfica, se tienen los valores observados (puntos con relleno), los valores estimados (puntos sin relleno) y el residuo (representado por una línea vertical que une a los valores observados con los estimados). Por tanto, puede imaginar ahora que cada dato (valor observado) tiene un valor estimado y un residuo (residuo ordinario en este caso) como se detalla a continuación:
| Rendimiento real | Rendimiento estimado | Residuo ordinario |
|---|---|---|
| 9.670 | 16.44451 | -6.774512 |
| 24.488 | 17.39127 | 7.096730 |
| 12.500 | 11.01095 | 1.489052 |
| 23.231 | 15.78590 | 7.445102 |
Luego dichos residuos se consideran como elementos clave en la evaluación del modelo ajustado. Estos suelen emplearse en los métodos de diagnosticos del modelo de regresión mediante pruebas de hipótesis acompañadas de inferencia visual (gráficos). Por ejemplo, la figura a continuación muestra una de las gráficas comunmente usadas en los métodos de diagnostico:
## Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
## "none")` instead.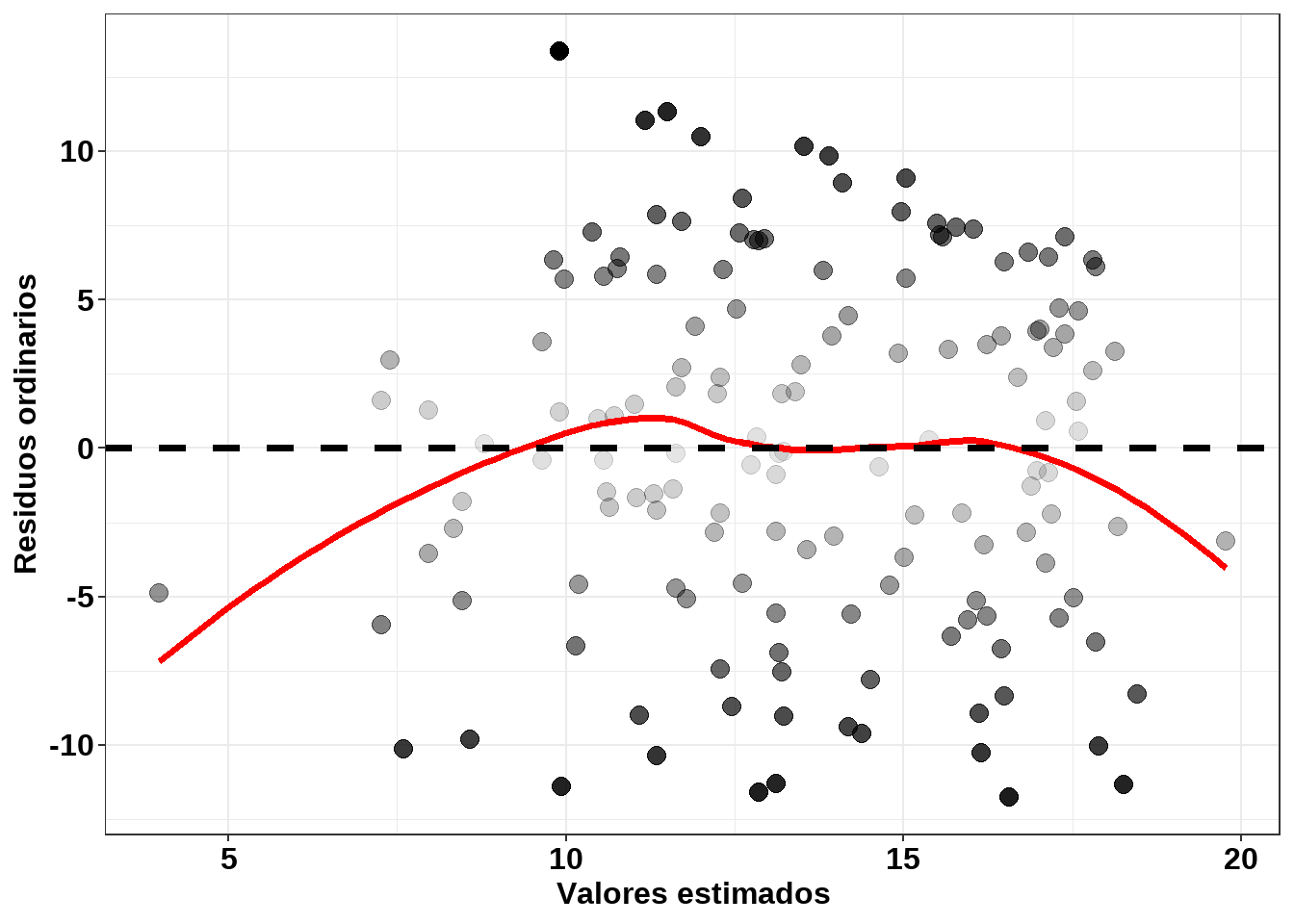
Figure 11.2: Gráfica de residuos ordinarios vs Valores estimados.
Veremos la interpretación de la misma con más detalle a continuación.
11.3 Diagnóstico del modelo de regresión: prueba de hipótesis e inferencia visual
Como es sabido, la inferencia estadística clásica consiste en formular inicialmente un juego de hipótesis (hipótesis nula y alternativa), y calcular posteriormente un estadístico de prueba del cual se deriva un valor p que permitira concluir en relación a las hipótesis planteadas. Este proceso tiene su análogo en inferencia visual.
Suponga que el interés consiste en verificar alguna suposición sobre el modelo ajustado, por ejemplo, la homogeneidad de la varianza residual. Para ello se plantea como hipótesis nula el cumplimiento de dicha homogeneidad, mientras que la hipótesis alternativa abarca cualquier violación de este supuesto. Para la inferencia visual, el estadístico de prueba corresponde a una gráfica que muestra un aspecto del supuesto que se desea verifcar, y permite al observador distinguir entre escenarios bajo la hipótesis nula y la alternativa.
A continuación se mostrará como llevar a cabo el diagnóstico del modelo de regresión empleando tanto pruebas de hipótesis como inferencia visual. Para ello, haremos uso de nuevo de la base de datos anteriormente mencionada hsb.
11.3.1 Ajustando el modelo
Vimos anteriormente en este capitulo que era posible determinar si el rendimiento de los estudiantes en una prueba de matemáticas (mathach) estaba relacionada con su nivel socio-económico (ses). Se considerará ahora la posibilidad de que la relación entre el rendimiento y el nivel socio-económico del estudiante varien según las características de la escuela, específicamente, si la escuela es una escuela pública o una escuela privada (schtype). Un buen punto de partida consiste es ver la relación entre el rendimiento y el nivel socio-económico por separado para cada escuela:
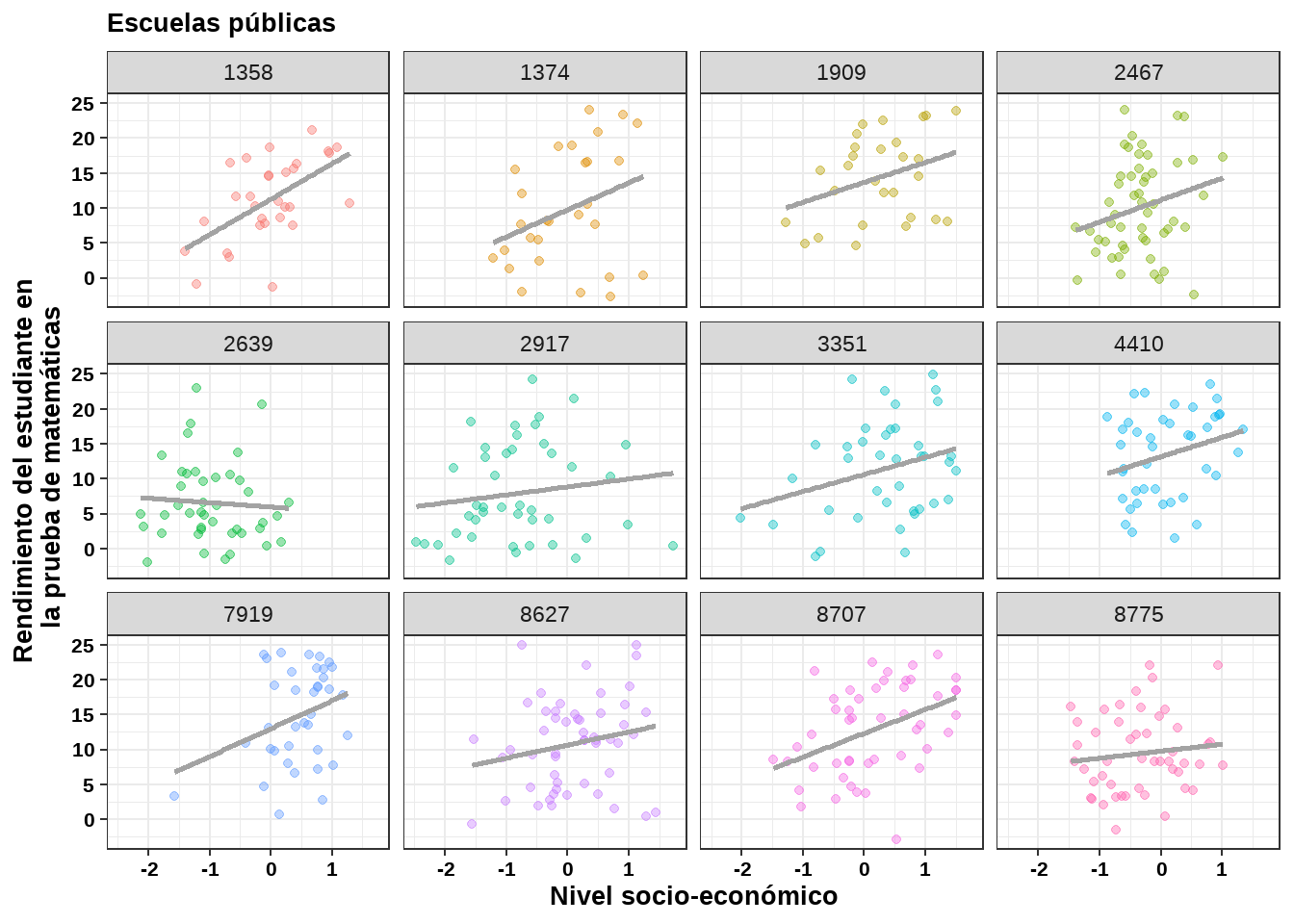
Figure 11.3: Diagrama de dispersión del rendimiento matemático según el nivel socio-económico en escuelas públicas.
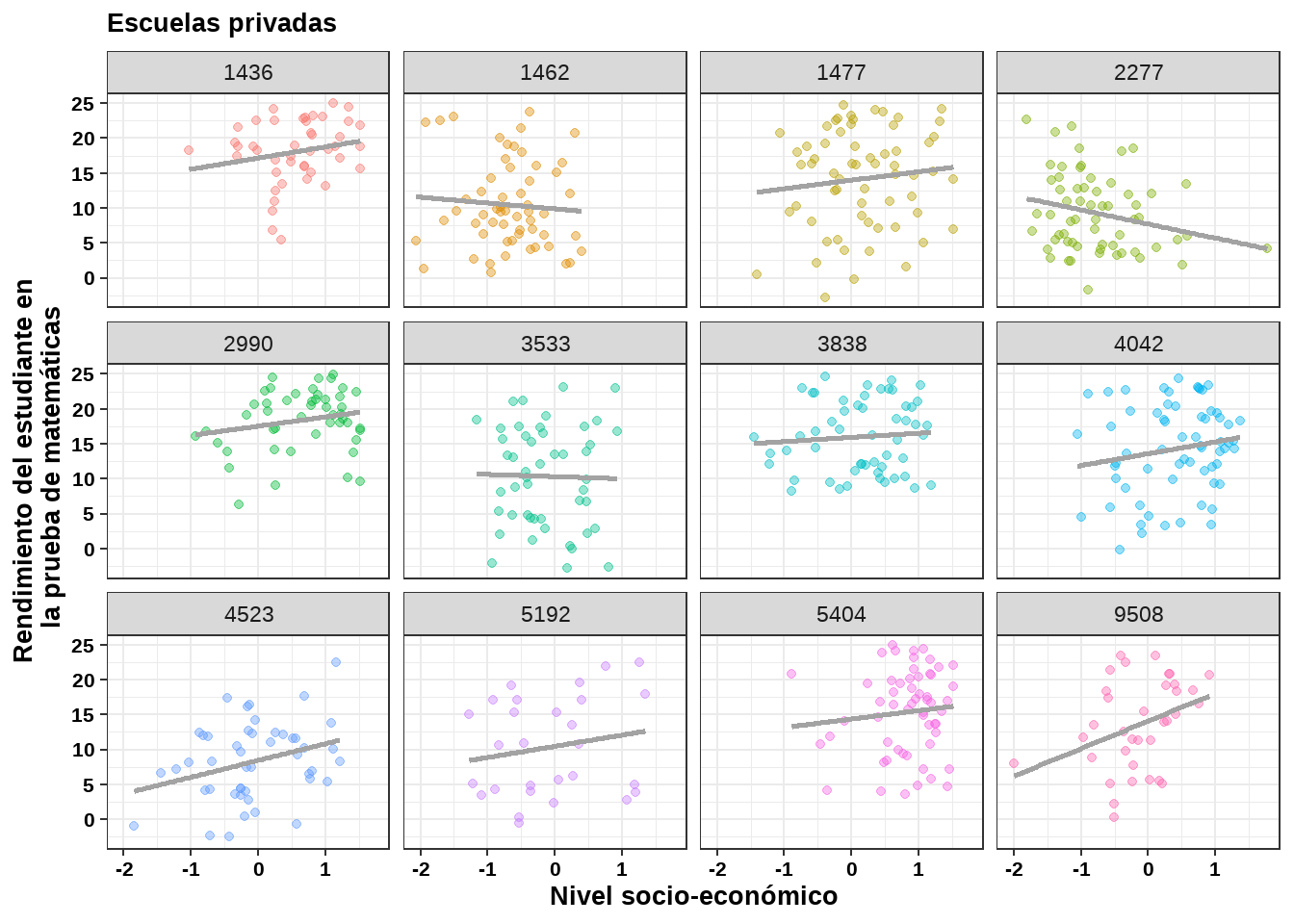
Figure 11.4: Diagrama de dispersión del rendimiento matemático según el nivel socio-económico en escuelas privadas.
En cada panel, la línea representa un ajuste lineal por mínimos cuadrados a los datos. El número en la parte superior corresponde a la identificación de la escuela (en este caso se han elegido doce escuelas para cada tipo). Claramente parece haber una diferencia entre la escuelas públicas y privadas: las líneas para las escuelas públicas parecen tener pendientes más pronunciadas. Esto hace pensar que un modelo de efectos mixtos con intercepto y pendiente aleatoria podría ser adecuado para modelar este tipo de datos.
Por tal motivo, el modelo de regresión de efectos mixtos aplicado a este ejemplo se puede representar así:
yij∼N(μij,σ2),μij=β0+β1xij+b0i+b1ixij,(b0b1)∼N[(00),(σ2b0σb01σb01σ2b1)]
Esta ecuación representa la relación existente entre el rendimiento acádemico y el nivel socio-económico de los estudiantes. La variable respuesta, yij, es el rendimiento del estudiante, i, en la escuela j.
El codigó en R para ajustar el anterior modelo se presenta a continuación. Se hara uso del paquete lme4 ya mencionado en el capitulo 3 del presente libro:
library(lme4)
Modelo_mixto <- lmer(mathach ~ ses + (ses | schtype),
REML = TRUE,
data = hsb)La siguiente figura, obtenida a partir del modelo anteriormente ajustado, pone de manifiesto la posibilidad real y plausible de que el intercepto y la pendiente varíen según las características de cada escuela (privada o pública):
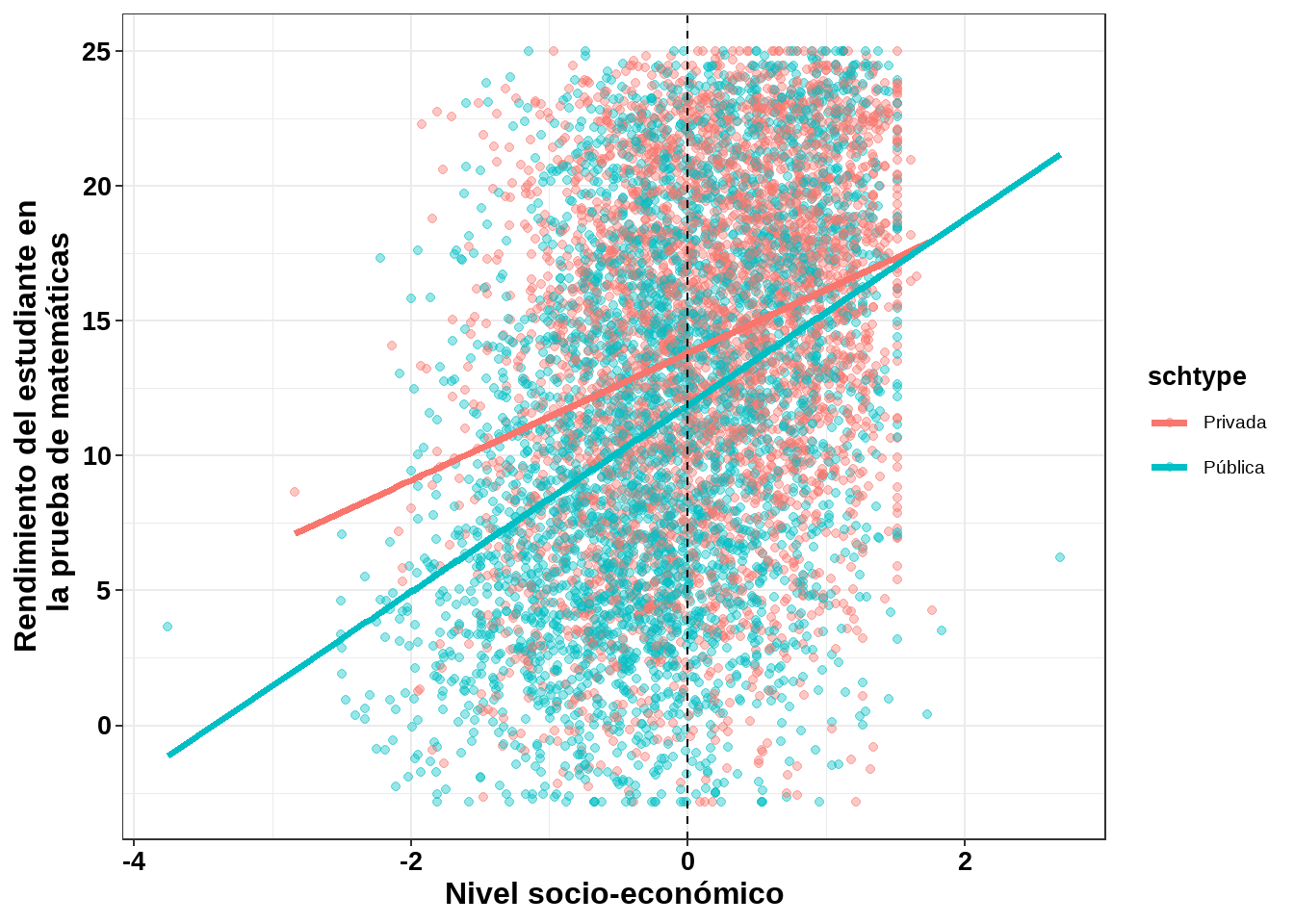
Figure 11.5: Grafica del modelo de regresión ajustado para dos escuelas.
Luego de ajustado el modelo de regresión, el procedimiento a seguir corresponde a evaluar el cumplimiento de los supuestos del mismo mediante métodos de diagnóstico.
11.3.2 Varianza constante de los residuos mediante inferencia visual
Uno de los supuestos del modelo de regresión es la varianza constante de los residuos. Para comprobar dicho supuesto, se suele emplear la gráfica de residuos contra los valores estimados. La misma es considerada como la gráfica de diagnóstico más básica. A continuación podrá observar varios ejemplos de la misma:
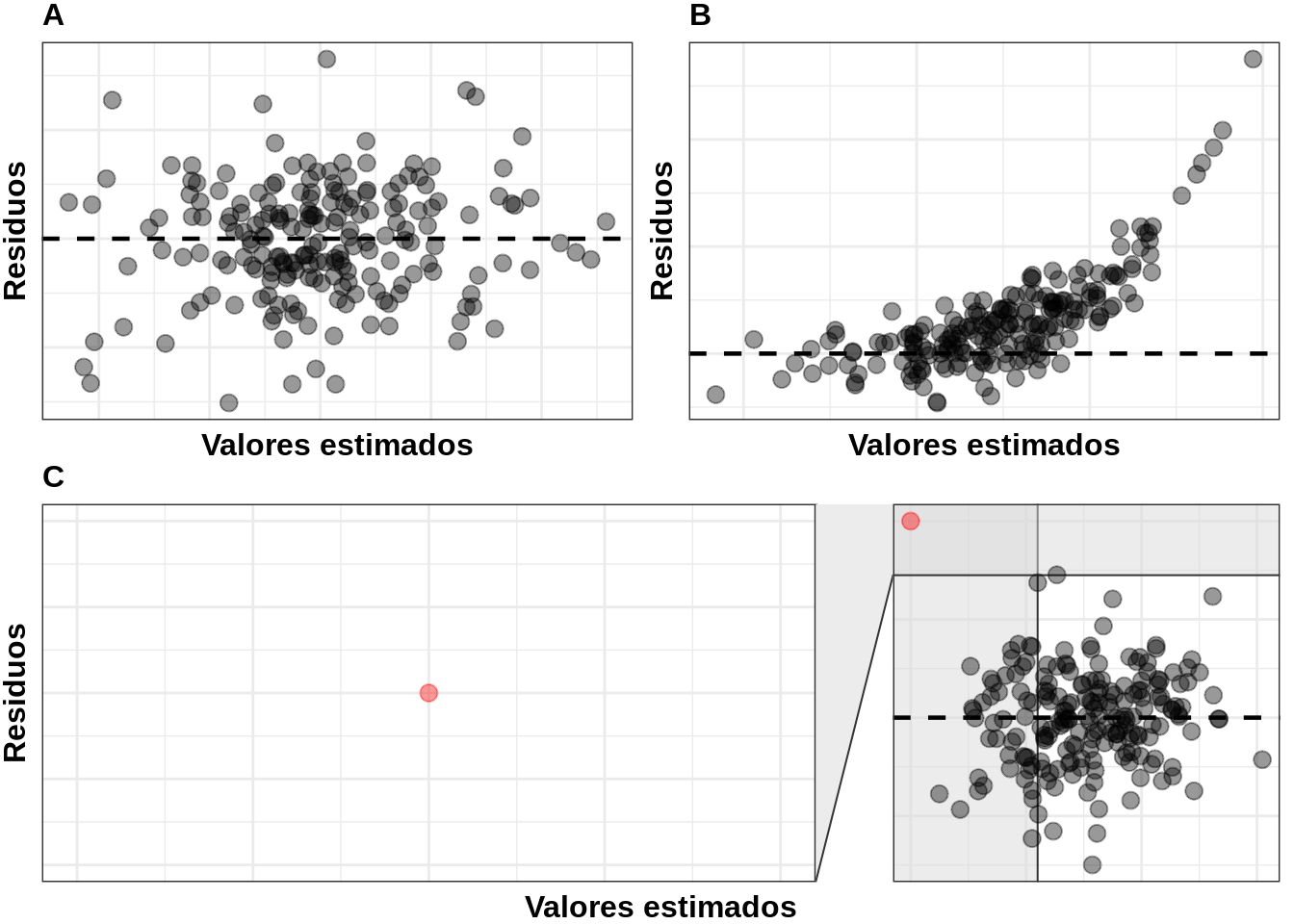
Figure 11.6: Representación visual de la gráfica de residuos contra los valores estimados.
Si se cumple el supuesto de varianza constante de los residuos, estos se dispersarían de forma aleatoria alrededor de la línea central (como si se tratara de una nube de puntos) sin un patrón obvio, como se puede observar en la figura 6.7 A. La varianza no constante se diagnosticaría si la variabilidad de los residuos en el gráfico mostraran un patrón no aleatorio, como por ejemplo, si hubiera una curvatura presente (figura 6.7 B), o bien, si los residuos cambiaran de forma abrupta a medida que aumentan los valores estimados. Finalmente, un patrón inusual puede ser causado por un valor atípico. En el ejemplo visual anterior (figura 6.7 C), se muestra un valor atípico obvio.
En el ejemplo planteado usando la base de datos hsb, esta gráfica se muestra en las figuras 6.8 A y 6.8 C, basados en dos tipos de residuos (ordinarios y pearson):
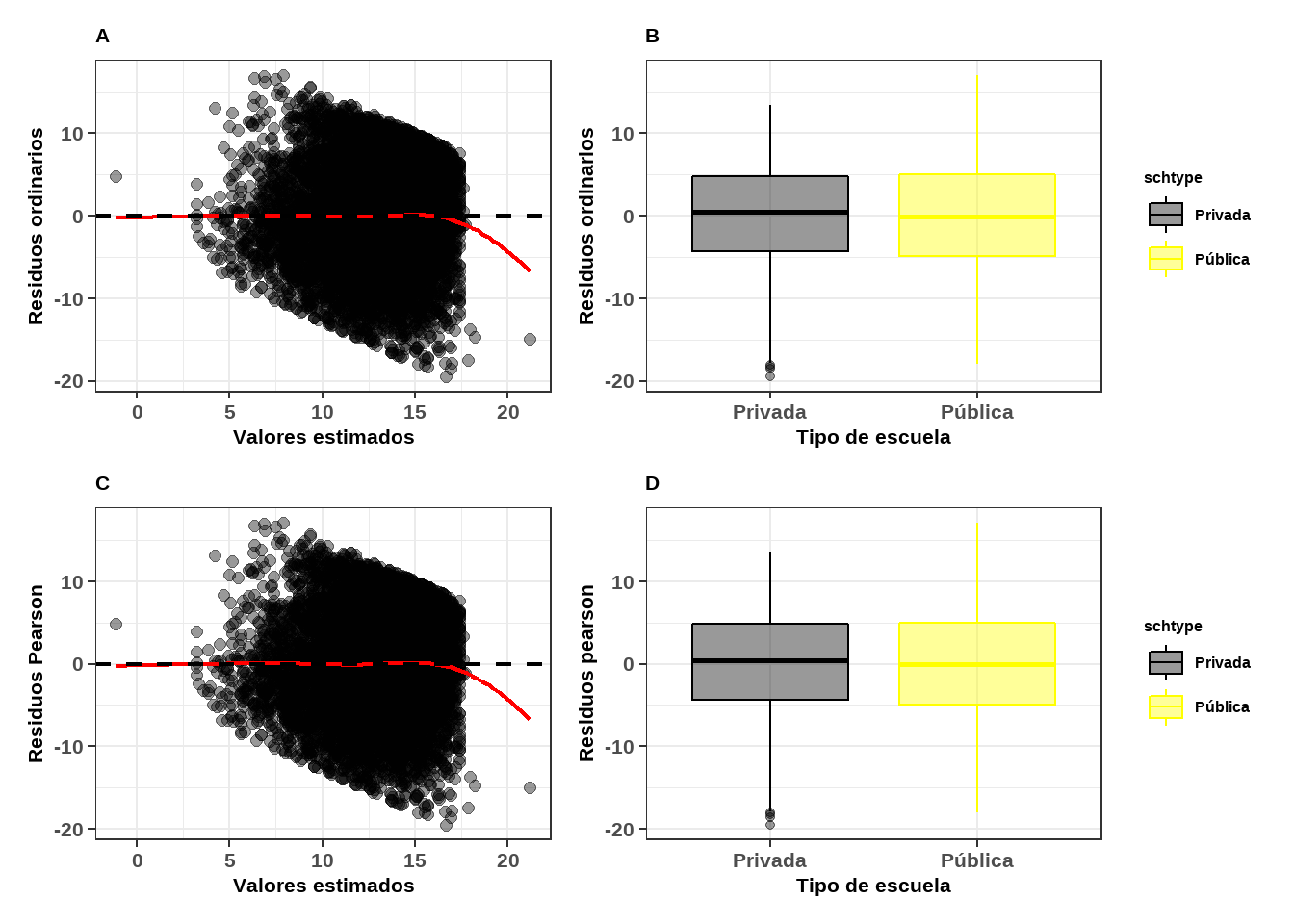
Figure 11.7: Gráficos residuales para el modelo de efectos mixtos (a) entre los residuos ordinarios contra los valores estimados (b) residuos ordinarios en cada tipo de escuela (c) residuos pearson contra los valores estimados (d) residuos pearson en cada tipo de escuela.
En relación al código presentado anteriormente, tenga en cuenta lo siguiente:
- Las gráficas se realizaron usando la función
ggplot(aquí subrayado en color amarillo) del paqueteggplot2; - Luego en la asignación estética (
aes), se proporcionó los valores estimados y los residuos pearson u ordinarios (aquí subrayados en color azul), datos que se obtuvieron mediante previo ajuste del modelo; - La línea discontinua en las gráficas superior e inferior izquierda, es la línea horizontal a través de ˆϵi=0 (es decir, donde la diferencia entre los valores observados y estimados son iguales a cero), siendo el mismo el caso ideal;
- La línea continua en rojo en las gráficas superior e inferior izquierda, obtenidas a partir de la función
stat_smoot(aquí subrayado en amarillo), representan una curva suave ajustada mediante el métodoloess, que indica la relación de los valores estimados con los residuos.
En general, los gráficos anteriores se evalúan de forma informal con respecto a la presencia o ausencia de patrones específicos y/o puntos de datos periféricos o aislados. Respecto a la línea de referencia en cero y la línea ajustada mediante el método de loess, estas deberían parecerse. Por otro lado en cuanto al gráfico de caja y bigotes (parte superior e inferior derecha de la anterior figura), si estas tienen aproximadamente el mismo centro y distancia intercuartil, indicarían el cumplimiento de varianza constante de los residuos.
11.3.3 Varianza constante de los residuos mediante prueba de hipótesis
Por lo general, es suficiente con interpretar de forma visual una gráfica de residuos contra valores estimados para comprobar la validez del supuesto de varianza constante de los residuos. Sin embargo, existen pruebas que pueden proporcionar una justificación adicional en el análisis. Dichas pruebas plantean el siguiente constraste de hipótesis:
H0:σ2ϵ1=σ2ϵ2
HA:σ2ϵ1≠σ2ϵ2
Así, H0 (la hipótesis nula) sugiere una varianza constante de los residuos. A continuación se mencionan algunas de estas pruebas:
| Prueba | Función en R | Paquete en R |
|---|---|---|
| Contraste de razón de varianzas | var.test | stats |
| Prueba de Levene | leveneTest | car |
| Prueba de Bartlett | bartlett.test | stats |
| Prueba de Brown-Forsyth | hov | HH |
| Prueba de Fligner-Killeen | fligner.test | stats |
| * La diferencias entre estas pruebas es el estadístico de centralidad que utilizan, así como también la sensibilidad o no al cumplimiento del supuesto de normalidad. |
Ejemplo
La función help y el operador de ayuda ? en R proporcionan acceso a las páginas de documentación para funciones de R, conjuntos de datos y otros objetos, así por ejemplo para acceder a la documentación de la función var.test del paquete stats, se puede ingresar el comando help(var.test) o help("var.test"), o ?var.test o ?"var.test" (por tanto, las comillas son opcionales).
Haciendo uso de cualquiera de los dos comandos de ayuda anteriores, se plantea como ejemplo acceder a la documentación de la función leveneTest del paquete car, y con ella evaluar por medio de la prueba de Brown-Forsyth si las varianzas de los errores de los dos tipos de escuela (privada y pública) de la base de datos hsb cumplen con el supuesto de varianza constante de los errores. Suponga un nivel de significancia igual a 0.05.
Para acceder a la documentación de ayuda de la función leveneTest del paquete car:
help("leveneTest", package = "car")Dicha documentación indica que el argumento y corresponde a la variable respuesta, group corresponde a la variable (factor) al que se desea evaluar la homogeneidad, y center donde se define el estadístico de centralidad. Para el ejemplo:
library(car)
leveneTest(y = hsb$res_ordinario, group = hsb$schtype, center = 'median')## Levene's Test for Homogeneity of Variance (center = "median")
## Df F value Pr(>F)
## group 1 20.102 7.456e-06 ***
## 7183
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Por lo tanto como el valor-P (7.456e-06) fue menor al nivel de significancia (0.05), se rechaza H0, lo que permite concluir que los dos tipos de escuela (privada y pública) presentan diferencias estadísticas significativas en la varianza de los errores.
11.3.4 Distribución normal de los residuos mediante inferencia visual
Los análisis de normalidad, también denominados como contraste de normalidad, son otro tipo de supuesto del modelo de regresión. Al igual que el supuesto de varianza constante de los residuos, en el análisis de normalidad se suele emplear representaciones gráficas. Esta representación consiste en la gráfica de probabilidad normal de los residuos, también denominada como gráfico cuantil cuantil. A continuación podrá observar un ejemplo de dichas representaciones en el caso del cumplimiento o no del supuesto de normalidad:
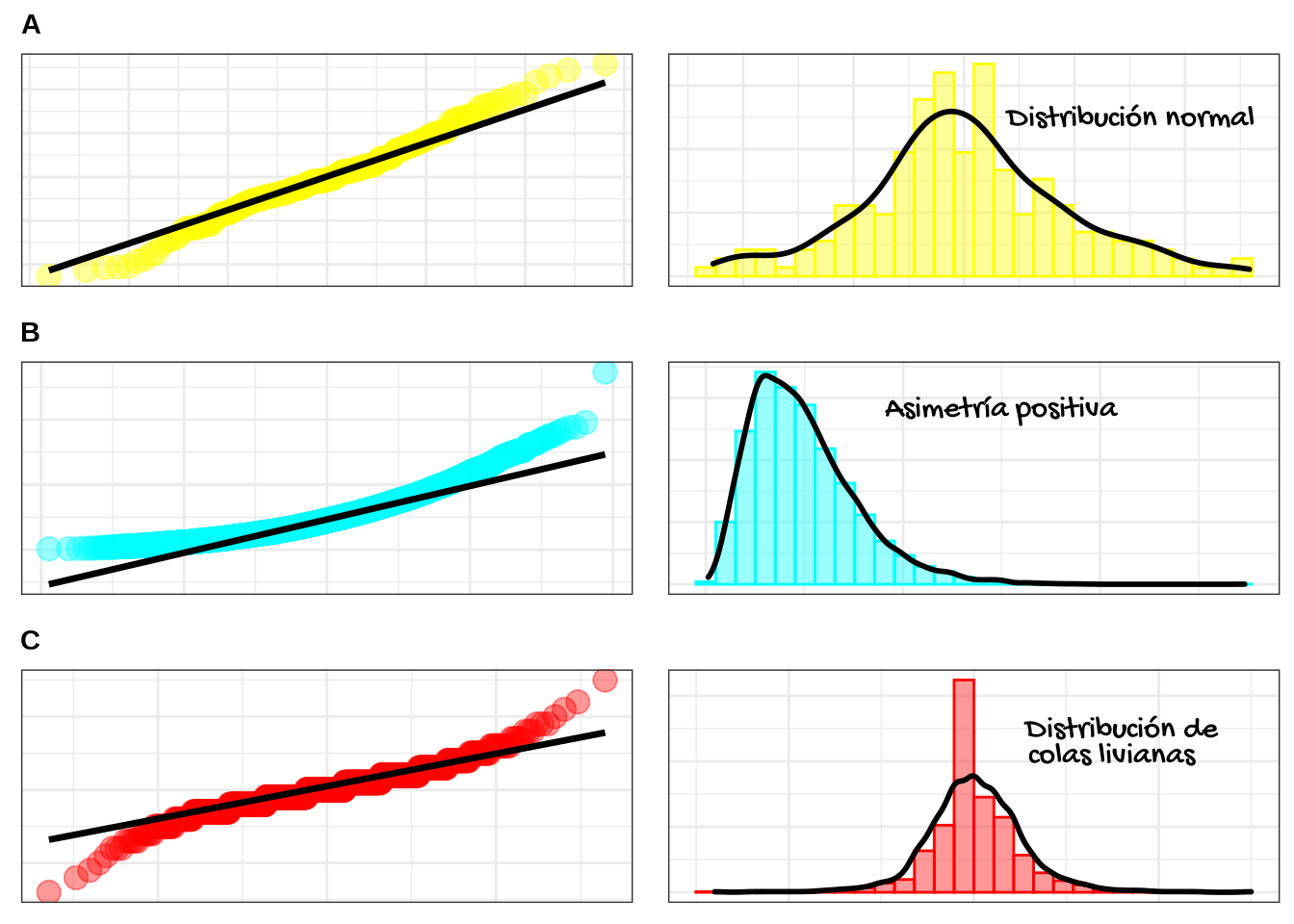
Figure 11.8: Ejemplo de distribución normal de los residuos y de aquellos residuos que no cumplen con este supuesto.
Si se cumple el supuesto de normalidad de los residuos, los puntos que constituyen la gráfica de probabilidad normal deberían alinearse entorno a la línea recta, como se puede observar en la figura 6.9 A (a la izquierda). Esta interpretación se evidencia al representar su equivalente mediante un histograma (figura 6.9 A a la derecha).
Las posibles causas de alejamiento a la normalidad se mencionan a continuación:
La variable respuesta podría tener muchos valores pequeños y pocos valores grandes, dando una representación de asimetría positiva (figura 6.9 B), o lo contrario, pocos valores pequeños y muchos valores grandes (asimetría negativa);
Al ajustarse el modelo y representar los residuos resultantes mediante un histograma, se podría observar una distribución de colas livianas producto de obtener pocos residuos de gran magnitud (figura 6.9 C), o bien, muchos residuos de gran magnitud podría conducir a una distribución de colas pesadas.
En el ejemplo planteado usando la base de datos hsb, la gráfica de probabilidad normal de los residuos se muestra en la figura a continuación.
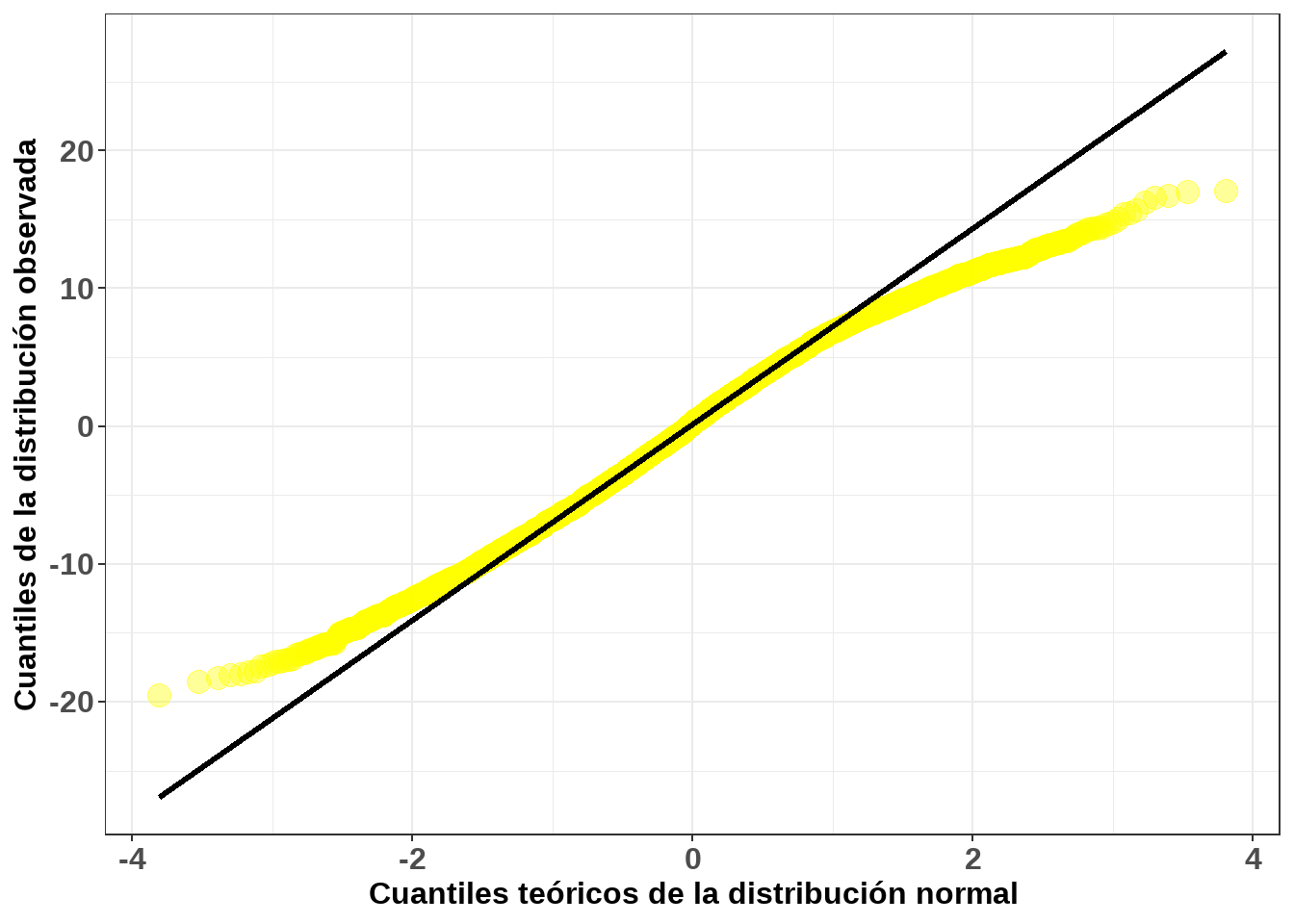
Figure 11.9: Gráfico cuantil cuantil para el modelo de efectos mixtos previamente ajustado.
En relación al código presentado anteriormente, tenga en cuenta lo siguiente:
- En la asignación estética (
aes) usando el paqueteggplot2, se proporcionó los residuos pearson (aquí subrayados en color azul), datos que se obtuvieron mediante previo ajuste del modelo; - A partir de la función
stat_qq(aquí subrayado en color amarillo), se dibuja la línea de puntos el cual indica la ubicación de los datos de acuerdo a los cuantiles de la distribución normal y de la distribución observada; - Con la función
stat_qq_line(aquí subrayado en color amarillo), se dibuja una línea recta. Si los puntos estan cerca a la misma, significa que los datos y la distribución normal tienen cuantiles comparables y se cumple el supuesto de normalidad de los residuos.
Ejemplo
En algunos casos es deseable identificar la distribución que siguen los datos en lugar de identificar la distribución que no siguen. Aswath Damodaran en el documento probabilistic approaches: scenario analysis, decision trees and simulation discute las características clave de las distribuciones más comunes, y en una de las figuras presentadas en dicho documento proporciona un diagrama de árbol para elegir una distribución. Un ejemplo del mismo (para datos continuos) se presenta a continuación:
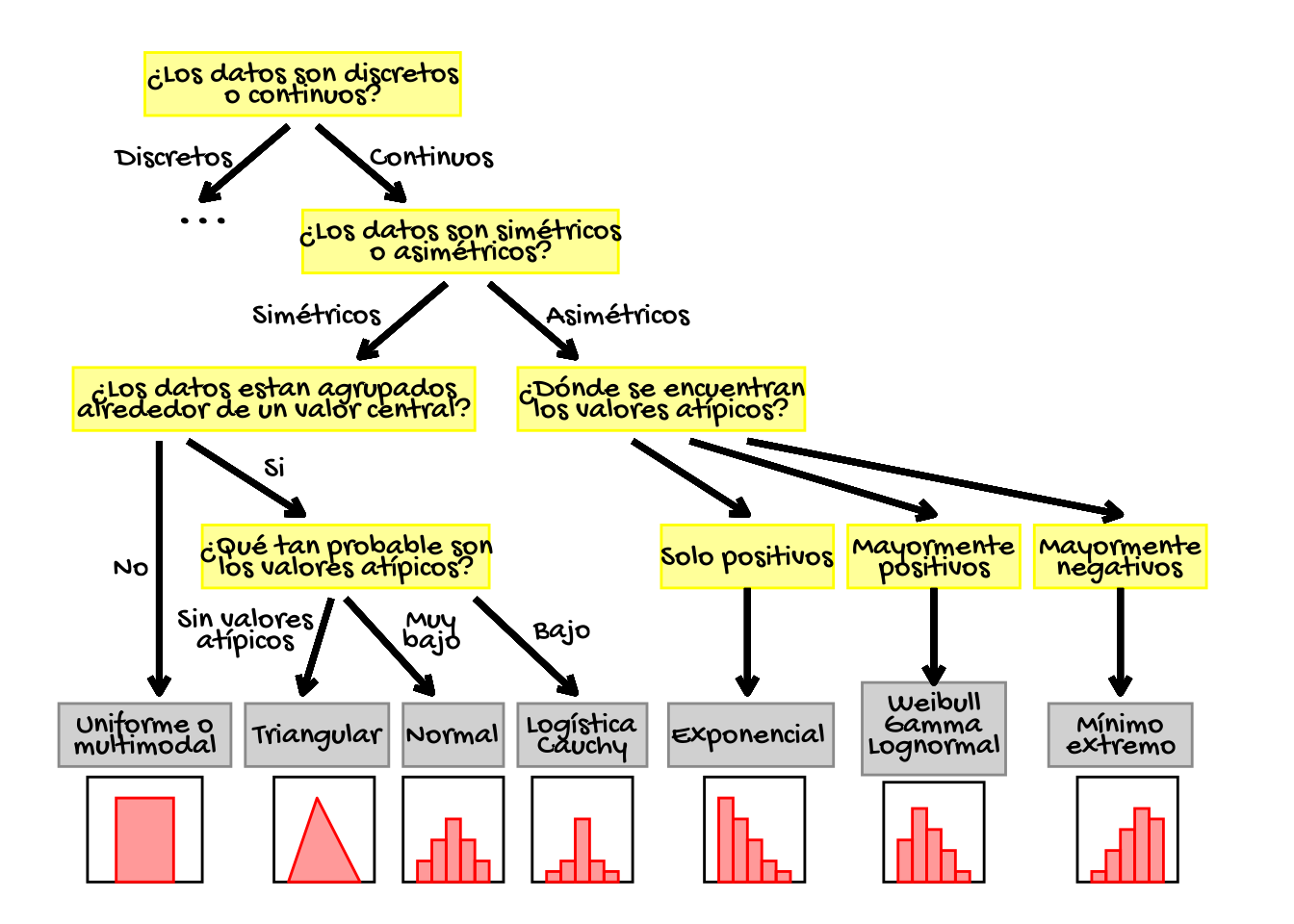
Figure 11.10: Diagrama de árbol para elegir el tipo de distribución de los datos, adaptado de Aswath Damodaran.
Al observar la figura 6.10 se puede concluir que el rendimiento en la evaluación en la prueba de matemáticas (mathach) de la base de datos hsb no cumple el supuesto de normalidad, una vez se aprecia que los puntos no están del todo alineados entorno a la recta, observándose unas ligeras desviaciones en las colas. En este sentido y haciendo uso del diagrama de árbol presentado con anterioridad, elija la distribución que más se acerca a la distribución presentada por dicho datos. Para ello le puede resultar útil construir un histograma.
ggplot(data = hsb, aes(x = res_pearson)) +
geom_histogram(aes(y = ..density..), bins = 8, colour = "yellow", fill = "yellow", alpha = 0.4) +
geom_density(size = 1.0, colour = "black") +
labs(x = "Residuos Pearson", y = "Frecuencia") +
theme_bw() +
theme(axis.text = element_text(size = 12, face = "bold"),
axis.title = element_text(size = 12, face = "bold"),
plot.title = element_text(size = 12, face = "bold"))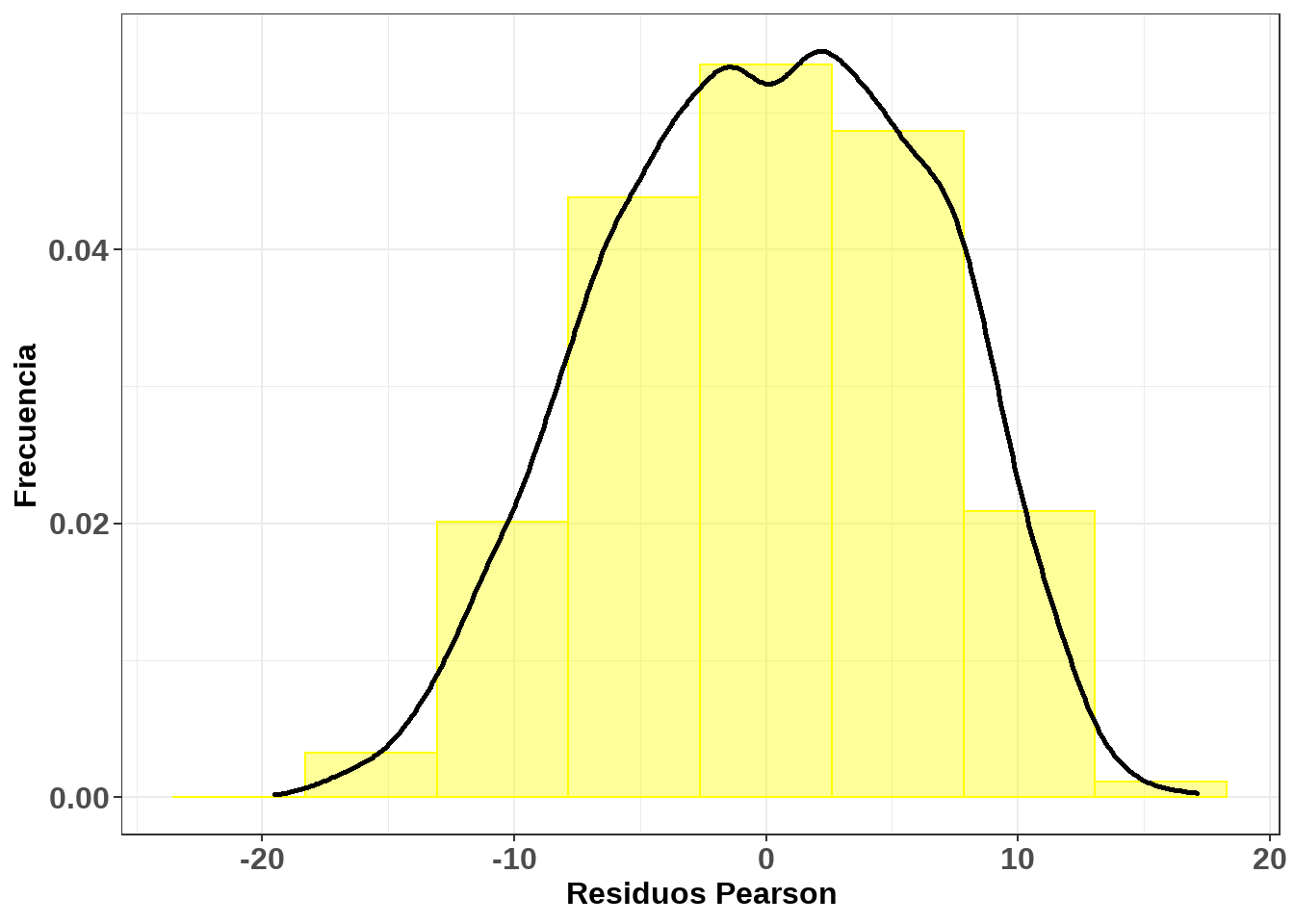
Figure 11.11: .
11.3.5 Distribución normal de los residuos mediante prueba de hipótesis
En el supuesto de normalidad de los residuos es posible realizar contraste de hipótesis que determinan si los datos siguen una distribución normal. Al igual que el supuesto de varianza constante, la prueba de distribución normal tiene una hipótesis nula (H0) y una hipótesis alternativa (HA):
H0:e∼N(0,σ2)
HA:e≁
Así, H_{0} (la hipótesis nula) sugiere una distribución normal de los residuos. A continuación se mencionan algunas de las pruebas estadísticas usadas para comprobar la validez del supuesto de normalidad de los residuos:
| Prueba | Función en R | Paquete en R |
|---|---|---|
| Shapiro-Wilk | shapiro.test | stats |
| Kolmogorov-Smirnov | ks.test | stats |
| Lillefors | lillie.test | nortest |
| Jarque-Bera | jarque.bera.test | tseries |
De las anteriores pruebas de distribución, un valor-P menor a un nivel de significancia previamente definido indica el rechazo de la hipótesis nula, lo que permite concluir que los datos no siguen la distribución normal de los residuos.